Watson Studio ist eine IBM Cloud Umgebung mit der Machine Learning Modelle und ganze KI Anwendungen erstellt, trainiert, verwaltet und eingerichtet werden können.
Watson Studio stellt ein Bündel von verschiedenen Werkzeugen zur Verfügung, wie z.B. Jupyter Notebooks oder IBM SPSS, und ermöglicht dadurch Data Scientists, Anwendungsentwickler und Fachbereichsbenutzer gemeinsam mit Daten zu arbeiten und diese zu analysieren.
Was ich persönlich sehr cool finde ist das Watson Studio den Einstieg in das Thema Machine Learning so einfach gestaltet. Ich kann loslegen und meinen ersten eigenen Modelle trainieren ohne der TensorFlow oder Apache Spark Experte zu sein. Für erfahrene Benutzer wird beides auch unterstützt, aber es ist eben nicht zwingende Voraussetzung für den Einstieg.
In diesem Tutorial möchte ich erste Schritte mit Watson Studio vorstellen, von der Einrichtung bis zur Erstellung eines ersten Machine Learning Modells.
Wichtig gleich vorab: Watson Studio und Watson Knowledge Studio sind zwei komplett verschiedene Sachen!
- Watson Knowledge Studio = Erstellung von Machine Learning Modellen zum Textverständnis (also exklusiv im Bereich „Natural Language Understanding“ / unstrukturierte Daten).
- Watson Studio = Erstellung von Machine Learning Modellen im Allgemeinen auf „Zahlen“-Basis (strukturierte Daten) unter Nutzung von Spark, TensorFlow, Visual Recognition, SPSS, auch Natural Language Understanding, usw. Watson Studio war früher auch unter dem Namen DSX (Data Science Experience) bekannt.
Bisher habe ich in meinem Blog hauptsächlich über Watson Knowlegde Studio geschrieben, möchte das nun um ein paar Artikel zum Watson Studio ergänzen und später auch beschreiben wie wir beide Werkzeuge gemeinsam verwenden können.
Watson Studio Service anlegen
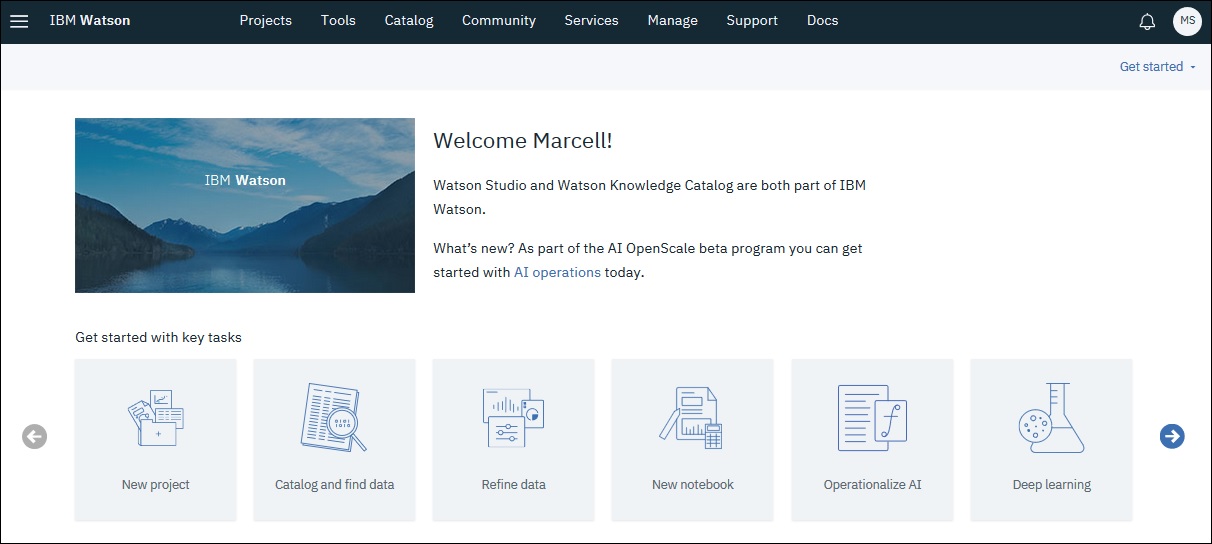
Um dieses Tutorial nachzuvollziehen benötigst du einen „Watson Studio“ Service in der IBM Cloud. Geh dazu auf den IBM Bluemix Catalog und melde dich mit deinem IBM Cloud Account an oder lege einen neuen Account an. Suche dann im Bluemix Katalog nach „Watson Studio“ und erzeuge eine neue Serviceinstanz.
Für unsere Tests genügt das kostenlose „Lite“ Paket. Nachdem der Service erstellt wurde klicke auf „Get Started“ um die Watson Studio Umgebung zu starten.
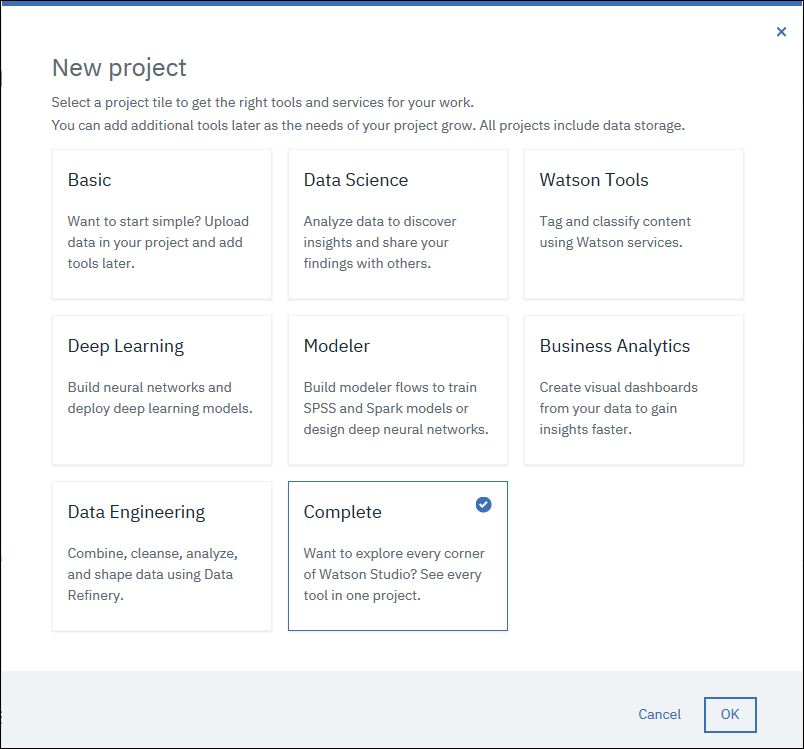
Neues Projekt anlegen
Mit „New project“ kannst du ein neues Projekt starten. „Complete“ ist erst mal die beste Auswahl an Features und Tools für uns.
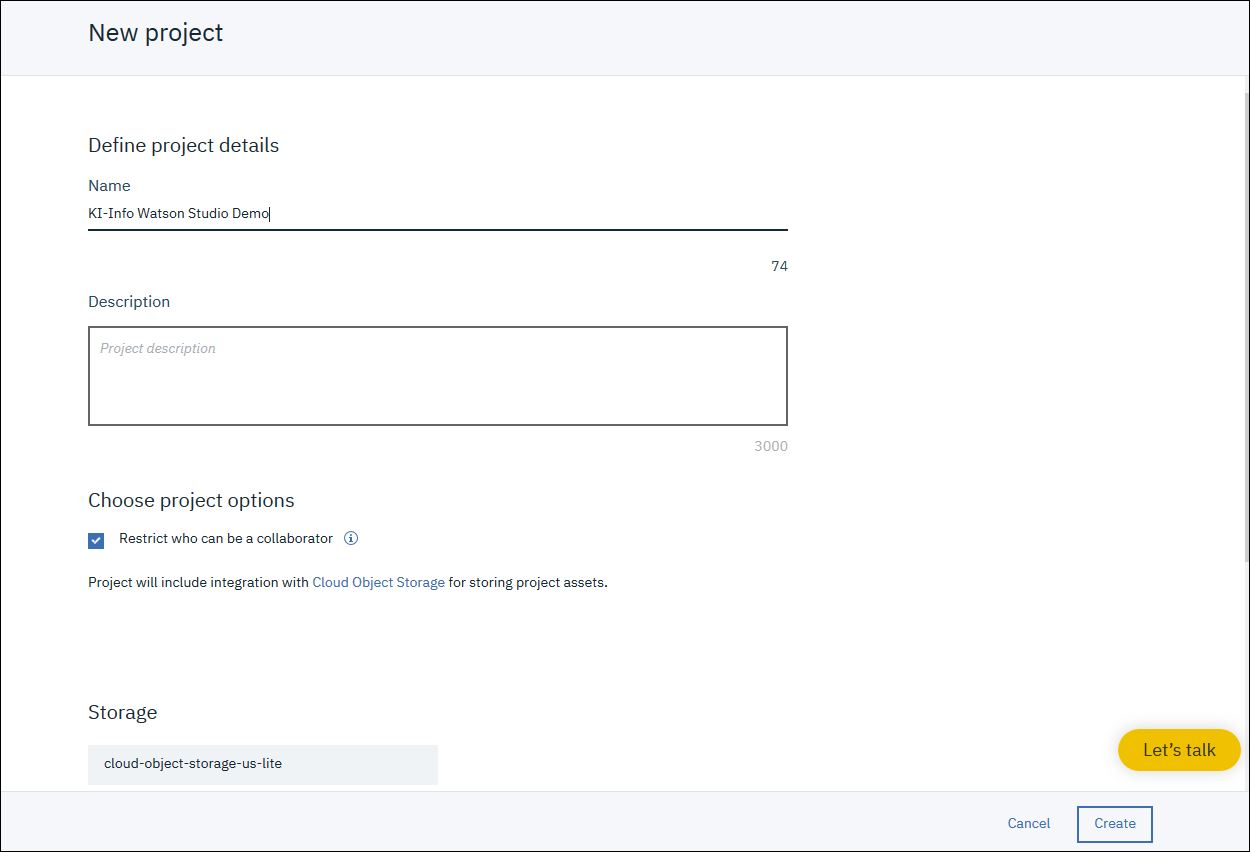
Vergib einen Namen für das Projekt und lege einen Storage Service an mit dem Type „Cloud Object Storage“ in der „Free“ Version.
In diesem Beispiel werden wir zwei verschiedene Machine Learning Algorithmen miteinander vergleichen und anschließend den Algorithmus der am besten unser Problem löst als Webservice zur Verfügung stellen.
Lade dazu zuerst die Datei customer_churn.csv runter und speichere sie lokal ab. Diese Datei enthält Beispiel-Kundendaten und im Feld CHURN die Information ob der Kunde abgewandert ist (T=True, F=False).

Über Drag und Drop kannst du die Datei ganz einfach in den rechten Bereich (Datenbereich) über „Drop files here…“ ablegen, oder du gehst auf „browse“ und wählst die Datei aus.
Gehe anschließend oben auf den Reiter „Settings“. Im Bereich „Associated Services“ klicke auf „Add Service“ und wähle „Spark“ aus. Wähle als Plan „Lite“ und klicke auf „Create“.
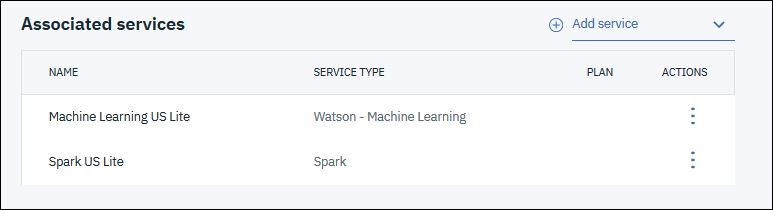
Das ganze wiederholen wir noch mal und legen einen weiteren Service vom Typ „Watson – Machine Learning“ an, als Plan ebenfalls wieder „Lite“.
Der Bereich „Associated Services“ sollte danach so aussehen (die Service-Namen werden bei dir anders sein, das ist kein Problem).
Machine Learning Modell anlegen
Gehe oben auf den Reiter „Assets“, dort zum Bereich „Watson Machine Learning models“ und klicke auf „New Watson Machine Learning model“.
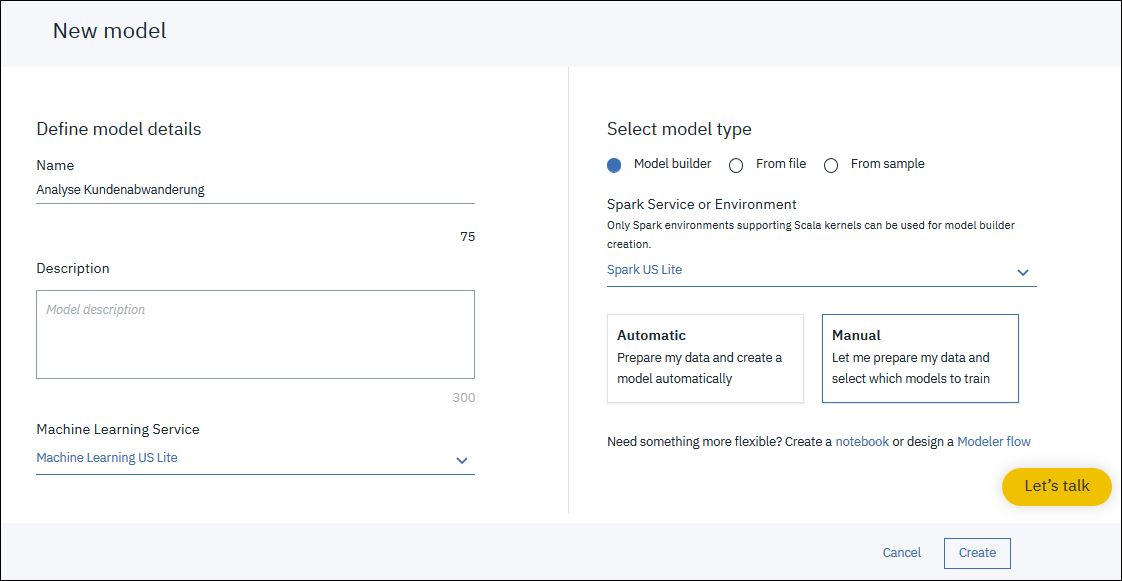
Als Name verwenden wir „Analyse Kundenabwanderung“. Überprüfe das als Machine Learning Service und Spark Service die beiden eben angelegten Services ausgewählt sind.
Wichtig: In der Auswahl „Automatic“ oder „Manual“ wähle bitte „Manual“, dadurch können wir das Modell selbst bestimmen. Klicke dann auf „Create“.
Als Data Asset wähle bitte die „customer_churn.csv“ Daten aus. Gehe dann auf „Next“.
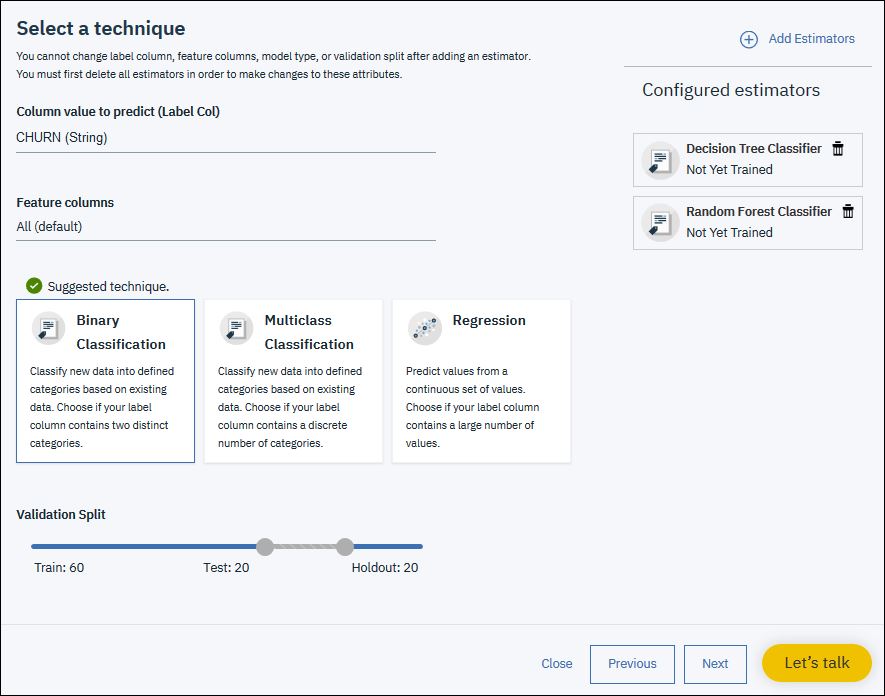
Setze „CHURN“ als „Column value to predict“. Die Auswahl „Feature columns“ lässt du auf „All“ und gehst auf „Binary Classification“.
Klicke dann auf „Add Estimators“ und füge „Decision Tree Classifier“ und „Random Forest Classifier“ hinzu. Gehe dann wieder auf „Next“.
Watson Studio trainiert jetzt zwei Machine Learning Modelle mit den beiden ausgewählten Algorithmen. Das Training selbst dauert ein paar Minuten, dann werden die Ergebnisse angezeigt.
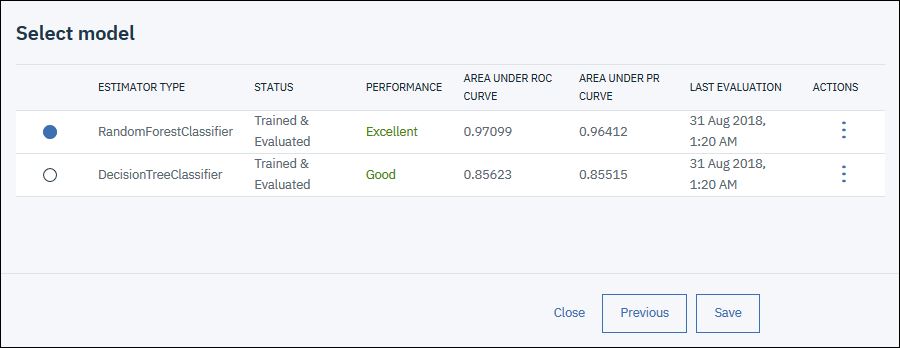
Der „Random Forest Classifier“ Algorithmus scheint auf unseren Daten am besten zu funktionieren, daher wählen wir diesen aus.
Mit „Save“ wird unser neues Machine Learning Modell gespeichert.
Machine Learning Modell deployen
Um das neue Modell nutzen zu können müssen wir es erst zur Verfügung stellen (deployen). Gehe dazu auf den Reiter „Deployments“ und wähle „Add Deployment“.
Gib als Name „Analyse Kundenabwanderung Deployment“ an. Der Deployment Typ bleibt auf „Web service“.
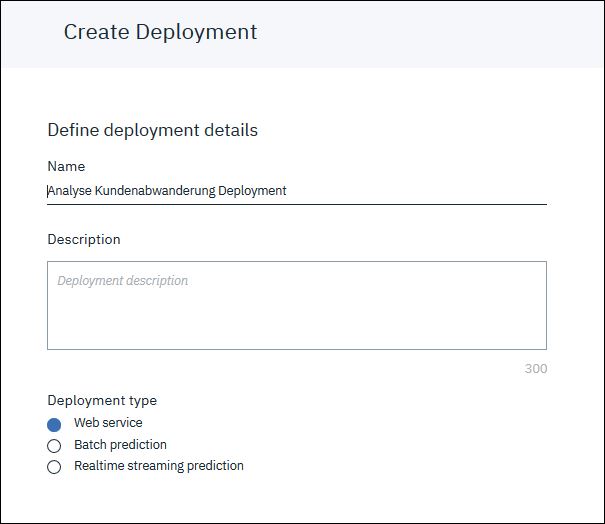
Nach dem Deployment klickst du auf das neue Deployment in der Liste. Auf dem Reiter „Implementation“ siehst du unter“Scoring End-point“ die URL über die unser neuer Webservice nun verfügbar ist.
Diese URL benötigen wir im nächsten Schritt.
Machine Learning Modell aufrufen über Jupyter Notebook
Unser Machine Learning Modell ist jetzt bereits unter der oben angegebenen URL verfügbar. Wenn wir es mit den Daten eines bestimmten Kunden aufrufen wird es uns Auskunft darüber geben ob wir diesen Kunden wahrscheinlich verlieren werden oder ob er uns treu bleiben wird.
Solch einen Aufruf können wir nun aus einem Jupyter Notebook heraus testen.
Lade dazu zuerst das Beispiel-Notebook herunter. Gehe dann in unserem Watson Studio Projekt auf „Assets“, „New Notebook“ im Bereich „Notebooks“, „From file“ und wähle über „Durchsuchen…“ die gespeicherte „Churn Model Access.ipynb“ Datei aus.
Den Namen kannst du so lassen oder ändern in „Aufruf Analyse Kundenabwanderung“.
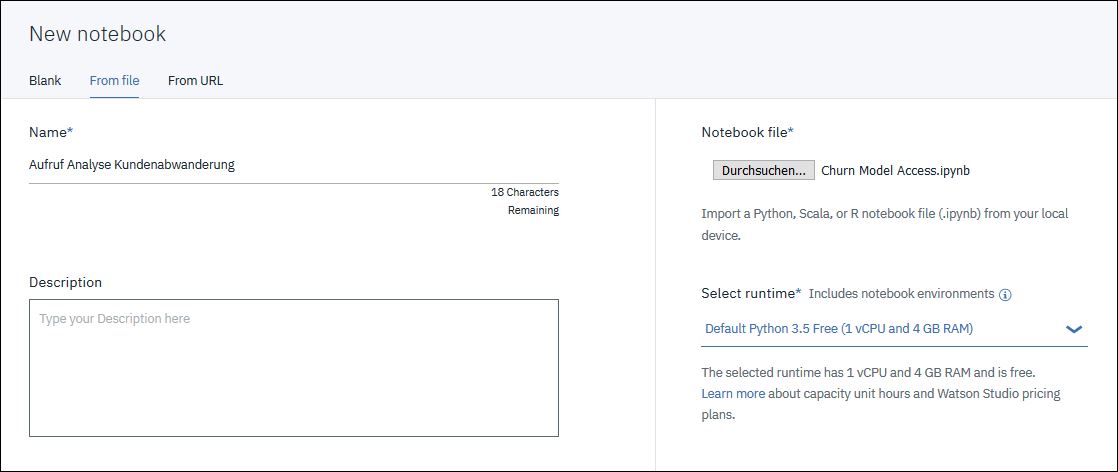
Nachdem das Notebook angelegt und gestartet ist müssen wir zuerst ein paar Konfigurationsparameter setzen.
Ersetze dazu in der ersten Zelle den Wert für das Feld wml_credentials mit den Service-Berechtigungsnachweisen deiner Watson Machine Learning Service Instanz.
Öffne dazu ein neues Browserfenster und gehe auf https://bluemix.net.
Klicke auf den oben angelegten Machine Learning Service in der Liste und gehe links in der Navigation auf „Serviceberechtigungsnachweise“ und dann rechts auf „Berechtigungsnachweise anzeigen“.
Du kannst über das Symbol an der rechten Seite den Berechtigungsnachweis komplett in die Zwischenablage kopieren und in das Jupyter Notebook einfügen.
Sollte dann in etwa so aussehen:
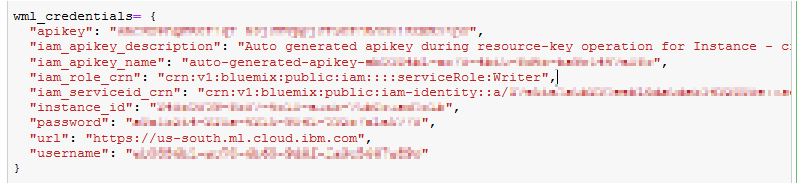
Ersetze anschließend noch den Wert für das Feld scoring_url mit der URL unter der dein eigenes Modell deployed wurde.
Führe nun über „Run“ die einzelne Zellen des Notebooks nacheinander aus.
Unser neues Modell wird nun mit zwei unterschiedlichen Kundendatensätzen aufgerufen und am Ende wird das Ergebnis dieses Aufrufs dargestellt.
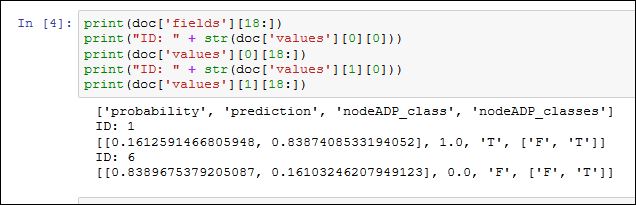
Diese – zugegebenermaßen erst mal etwas schwer zu verstehende – Ergebnis gibt an das für den ersten Kundendatensatz eine Abwanderung des Kunden wahrscheinlich ist (nodeADP_class = T = True) mit 83,87% Zuverlässigkeit.
Für den zweiten Kundendatensatz ist eine Abwanderung unwahrscheinlich (nodeADP_class = F = False) mit 83,90% Zuverlässigkeit.
Der Prozentwert gibt dabei an wie sicher sich das Machine Learning Modell ist das die getroffene Aussage stimmt.
Herzlichen Glückwunsch, damit hast du dein erstes eigenes Machine Learning Modell trainiert und es nach außen hin verfügbar gemacht. Jeder mit der richtigen End-point URL und den passenden Service-Berechtigungsnachweisen kann nun dein Modell weltweit aufrufen und eine Vorhersage der Kundenabwanderungswahrscheinlichkeit bekommen.
Wie geht es weiter?
Ein sehr gutes Tutorial zu Watson Studio in Englisch findet ihr hier:
IBM® Watson Studio – ML/DL made easy
Dieses Tutorial beschreibt – neben der Analyse die wir gerade eben gemacht haben – noch ein paar weitere Funktionalitäten von Watson Studio:
- Einbindung von Watson Services anhand des Language Translator Service
- Training und Nutzung des Visual Recognition Services zur Bildklassifizierung
- Nutzung des Modellierungswerkzeugs für neuronale Netzwerke
- Testen von neuronalen Netzwerken