Nach dem wir in den vorherigen Teilen dieser Serie über maschinelles Lernen mit WKS ein Textanalysemodell trainiert haben, möchte ich in diesem Artikel beschreiben wie wir dieses Modell nun in den verschiedenen IBM Watson Diensten anwenden können um damit eine große Anzahl von Texten zu verstehen.
Für das maschinelle Lernen selbst haben wir IBM Watson Knowledge Studio (WKS) verwendet. Watson Knowledge Studio bietet uns einen intuitiven Weg Expertenwissen vom Menschen auf ein Textanalysemodell zu übertragen.
Das fertig trainierte Textanalysemodell können wir nun in verschiedenen IBM Watson Diensten einsetzen. Unser System hat gelernt was für uns wichtige Begriffe und Zusammenhänge sind und kann dieses Wissen auf eine große Menge von neuen Inhalten anwenden, diese lesen und verstehen und die für uns wichtigen Informationen extrahieren.
Und das natürlich viel schneller als wenn wir selbst jeden dieser Texte lesen müssten.
Dazu können wir entweder cloudbasierte Dienste verwenden oder wir können die Verarbeitung auch komplett „On Premise“ auf einer eigenen Infrastruktur laufen lassen.
Dies ist der fünfte Teil meiner Artikelserie zum IBM Watson Knowledge Studio in Deutsch. Eine Einführung in WKS gibt es hier: Maschinelles Lernen in der Praxis: IBM Watson Knowledge Studio
Die Erstellung des Modells mittels maschinellem Lernen habe ich hier beschrieben: Machine Learning Modell trainieren mit Watson Knowledge Studio
Nach Training und Evaluierung des Modells kommen wir irgendwann mal an den Punkt an dem wir mit der Qualität hinreichend zufrieden sind um es mit neuen, unbekannten Texten zu versuchen.
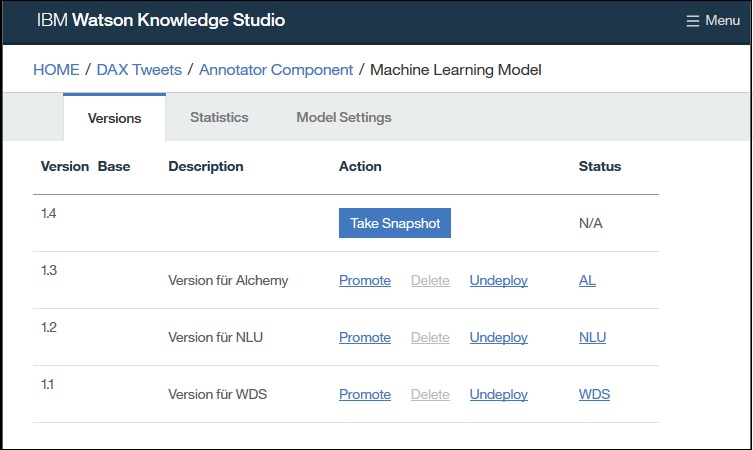
Dazu legen wir zuerst einmal einen Snapshot des aktuellen Modells an. Snapshots werden in WKS in einer Versionshistorie gehalten, dadurch kann ich jederzeit zu einem vorherigen Snapshot zurückkehren.
Die erstellten Snapshots kann ich dann in folgenden IBM Watson Diensten und Produkten verwenden:
- Natural Language Understanding
IBM Bluemix Dienst für die Analyse von unstrukturierten Inhalten. Dieser Dienst war bisher auch unter dem Namen „Alchemy Language API“ bekannt.
- Watson Discovery Service
IBM Bluemix Dienst für eine kognitive Suche mit Inhaltsanalyse.
- IBM Watson Explorer
IBM Produkt (On Premise) um Such- und Content-Analyse-Funktionen mit Cognitive-Computing-Funktionen zu kombinieren.
Ein Snapshot kann immer nur auf genau einem Dienst bereitgestellt werden. Man kann aber mehrere Snapshots von einer Version machen um das gleiche Modell auf mehreren Diensten einzusetzen.
Natural Language Understanding API / Alchemy Language API
Mit der Natural Language Understanding API (NLU) können Textanalysen durchgeführt werden, um Metadaten wie z. B. Konzepte, Entitäten, Schlüsselwörter, Kategorien, Stimmungen, Emotionen, Beziehungen und semantische Rollen aus Inhalten zu extrahieren. Dafür kann man ohne zusätzlichen Aufwand die in NLU vorhandenen Textanalysemodelle nutzen.
Mit Hilfe von Watson Knowledge Studio können wir darüber hinaus benutzerdefinierte Annotationsmodelle entwickeln um branchen- und domänenspezifische Entitäten und Beziehungen in unstrukturiertem Text zu identifizieren.
Die NLU API ist über IBM Bluemix verfügbar. Aktuell können 1.000 Entitäten pro Tag kostenfrei aus dem Text extrahiert werden. Die NLU API ist funktional weitgehend identisch zur Alchemy Language API, welche Anfang 2018 endgültig durch die NLU API abgelöst wird. Daher sollte in neuen Projekten die NLU API verwendet werden.
WKS Modell in NLU API bereitstellen
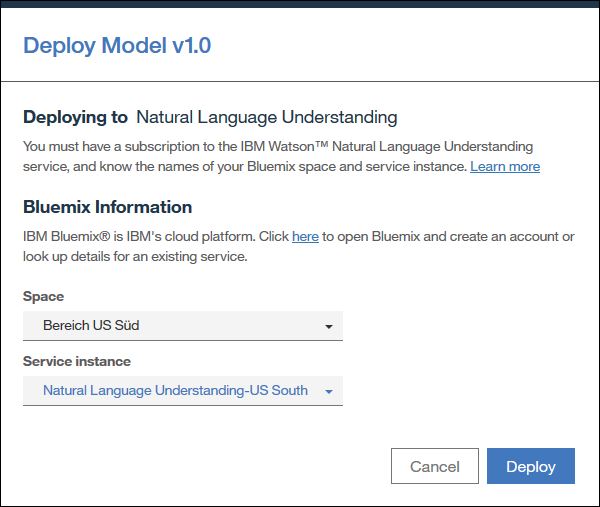
Um ein eigenes Textanalysemodell in der NLU API verwenden zu können muss man zuerst eine neue Instanz dieser API im IBM Bluemix Konto anlegen.
Wichtig: Wenn ihr die Gratisversion von WKS benutzt dann müsst ihr die NLU Instanz im Bereich „US Süd“ anlegen damit diese in WKS als Ziel zur Verfügung steht.
Anschließend könnt ihr in WKS das Modell in der NLU Instanz bereitstellen:
Nach dem die Bereitstellung gestartet wurde bekommen wir die Modell ID angezeigt. Diese ID muss beim Aufruf der API mitgegeben werden um das Textanalysemodell zu nutzen.
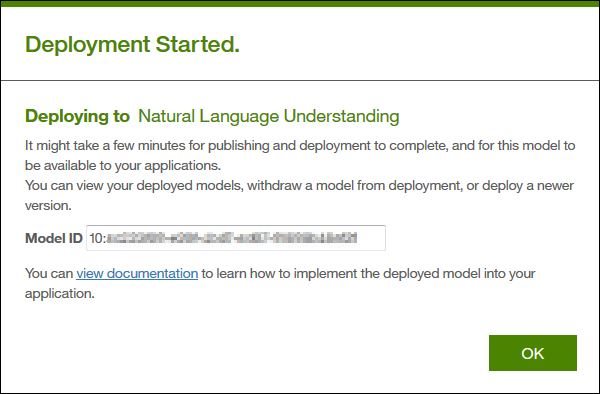
Die Bereitstellung selbst dauert ein paar Minuten. In WKS kann über den NLU Link in der Status Spalte geprüft werden wann die Bereitstellung abgeschlossen ist.
Test der NLU API
Die NLU API selbst bietet leider keine Benutzeroberfläche, es ist vorgesehen das sie komplett über REST API Aufrufe genutzt wird.
Es steht zwar unter https://natural-language-understanding-demo.mybluemix.net/ eine Demo zur Verfügung, dort kann ich aber keine eigenen Modelle verwenden. Dazu müsste ich dann schon die Demoanwendung modifizieren, diese liegt im Quellcode vor und kann jederzeit angepasst werden.
Für einen ersten Test ist es am sinnvollsten den NLU API Explorer zu verwenden:
https://watson-api-explorer.mybluemix.net/apis/natural-language-understanding-v1
Zuerst geben wir oben rechts die Berechtigungsnachweise des NLU Dienstes ein (Benutzername und Kennwort).
Die Anmeldeinformationen können wir in der Bluemix Konsole für den NLU Dienst finden („Servicedetails“ > „Serviceberechtigungsnachweise“ > „Berechtigungsnachweise anzeigen), das sind nicht die „normalen“ Bluemix Account Anmeldedaten! !
Dann öffnen wir in den Bereich „GET /v1/analyse“ und passen folgende Parameter an:
- Parameter „text“: Der zu analysierende Text:
Trendbestätigung für LONG im #DAX mit Ziel 12100 Punkte - Parameter „features“: Nur „entities“ auswählen.
- Parameter „entities.model“: Hier geben wir unsere Modell Id von oben an.
Durch Klick auf die „Try it out!“ Schaltfläche wird der Aufruf abgesetzt und wir bekommen darunter das Ergebnis angezeigt:
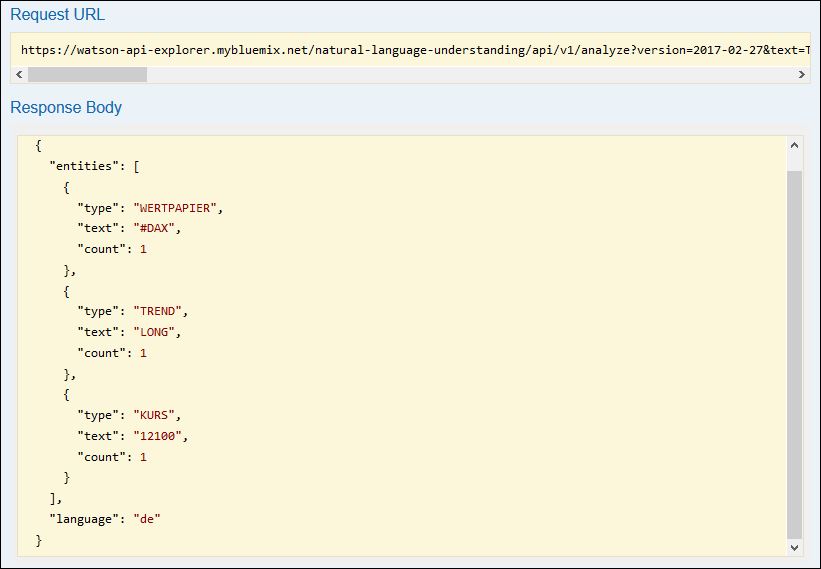
Was sehen wir hier nun? Unser Text „Trendbestätigung für LONG im #DAX mit Ziel 12100 Punkte“ wurde erfolgreich durch unser eigenes Modell analysiert und es wurden die Entitäten WERTPAPIER, TREND und KURS gefunden.
Wir wissen jetzt das es in dem Text um den DAX geht, ein Trend beschrieben wird und ein Kurswert angegeben wird. Das alles ohne das wir den Text selbst hätten lesen müssen.
Diesen API Aufruf (im Feld „Request URL“ angegeben) könnten wir nun automatisch auf alle interessanten hunderten Tweets laufen lassen und dann zum Beispiel nur die Tweets weiterverarbeiten in denen für den DAX ein Trend mit Kursziel genannt wird.
Beziehungen in NLU
Um auch die Beziehungen zwischen den Entitäten angezeigt zu bekommen müssen wir noch folgende Parameter im API Explorer setzen:
- Parameter „text“: Bleibt unverändert.
- Parameter „features“: Diesmal „entities“ und „relations“ auswählen.
- Parameter „entities.model“: Bleibt unverändert.
- Parameter „relations.model“: Gleiche Modell Id wie in „entities.model“ angeben.
Damit bekommen wir nun folgendes Ergebnis angezeigt:
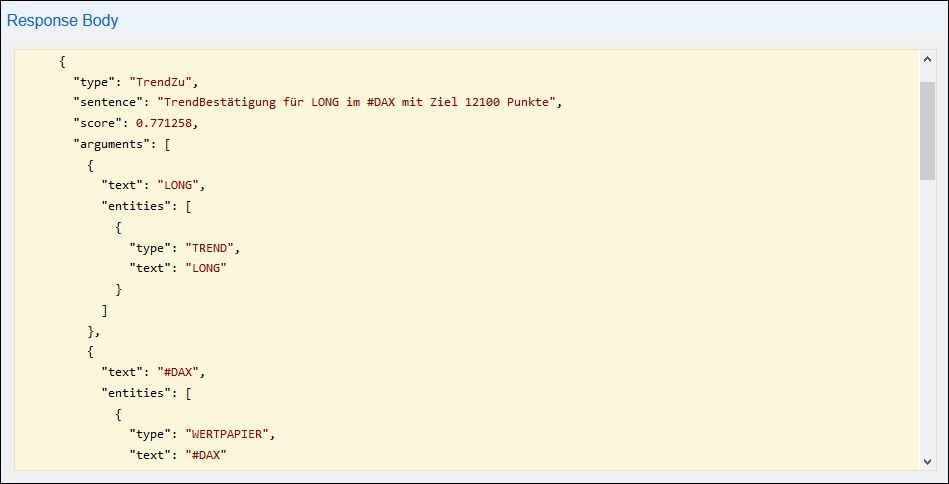
Hier sehen wir eine Beziehung „TrendZu“ welche eine Verbindung zwischen dem gefundenen Trend und dem gefundenen Wertpapier beschreibt. Genau so gibt es auch die Beziehung „KursZu“ zwischen Kurs und Wertpapier. usw.
Watson Discovery Service
Der Watson Discovery Service (WDS) bietet eine kognitive Suche mit Inhaltsanalyse im Rahmen einer cloudbasierten API.
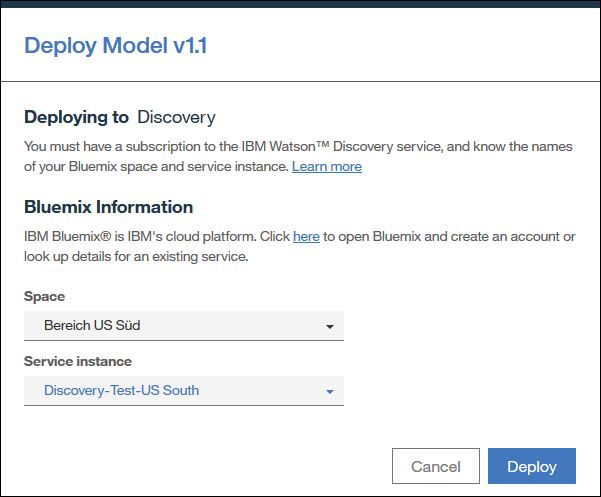
Auch hier müssen wir wieder zuerst eine Instanz dieses Dienstes in unserem Bluemix Konto anlegen um damit dann ein eigenes Textanalysemodell verwenden zu können. Bei Nutzung der Gratisversion von WKS muss auch hier der Dienst im Bereich „US Süd“ anlegt sein.
Watson Discovery Service in IBM Bluemix
Ansonsten läuft die Bereitstellung für Watson Discovery Service identisch zur Bereitstellung für den Natural Language Understanding Dienst, zumindest auf Seiten von WKS.
Im Watson Discovery Service ist die Einbindung eines eigenen Modells etwas komplizierter, aber zumindest gut dokumentiert. Die einzelnen Schritten sind hier beschrieben:
https://www.ibm.com/watson/developercloud/doc/discovery/integrate-wks.html
Im Wesentlichen muss man eine neue Collection anlegen und die Konfiguration dieser Collection anpassen so das in der Analyse der neuen Dokument das eigene Textanalysemodell verwendet wird.
Der Watson Discovery Service bietet eine Administrations- und Testoberfläche um auf die Bestandteile des Dienstes zuzugreifen. Über diese Oberfläche kann man auch einfach über „Drag & Drop“ neue Dokumente zu einer Collection hinzufügen.
Um die Administration zu starten wechseln wir in Bluemix auf die Servicedetails von WDS und klicken auf die Schaltfläche „Launch tool“.
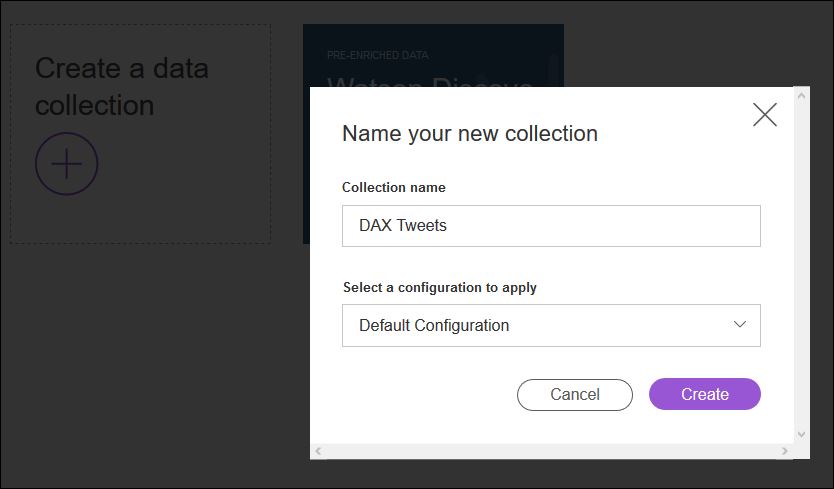
Zuerst einmal legen wir uns über das „+“ eine neue Collection (Sammlung) an.
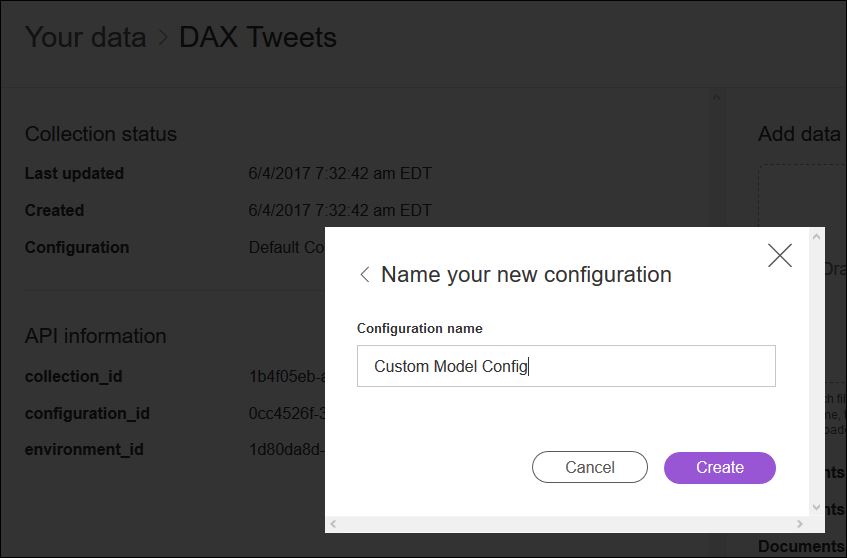
Danach öffnen wir die Infoseite der neuen Collection, klicken bei „Configuration“ auf „Switch“ und legen eine neue Konfiguration an:
Jetzt wirds dreckig 🙂 Die folgenden Schritte sind leider aktuell noch nicht in der UI verfügbar und müssen daher über Kommandozeilenaufrufe gemacht werden.
Zuerst einmal müssen wir die aktuelle Konfiguration der Collection herunterladen. Dazu im folgenden Aufruf die Platzhalter {environment_id} und {configuration_id} ersetzen. Die notwendigen Werte bekommen wir aus der Detailinfoseite der soeben angelegten Collection. Username und Password bekommen wir über die Serviceberechtigungsnachweise unserer WDS Instanz.
curl -u "{username}":"{password}" "https://gateway.watsonplatform.net/discovery/api/v1/environments/{environment_id}/configurations/{configuration_id}?version=2016-12-01" > wks_config.json
Dadurch wird eine Datei „wks_config.json“ angelegt mit der aktuellen Konfiguration. Diese Datei müssen wir nun mit einem Texteditor bearbeiten und die ID unseres Modells im Bereich „enrichments“ als Parameter „model“ hinzufügen.
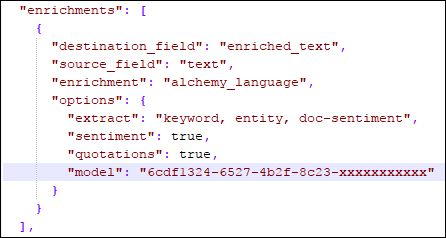
Als nächstes muss die angepasste Konfiguration wieder hochgeladen werden. dazu wie gehabt die Platzhalter {environment_id} und {configuration_id} ersetzen.
curl -X PUT -u "{username}":"{password}" -H "Content-Type: application/json" -d @wks_config.json "https://gateway.watsonplatform.net/discovery/api/v1/environments/{environment_id}/configurations/{configuration_id}?version=2016-12-01"
Damit können wir nun direkt erste Tweets als HTML hochladen. Das kann man automatisch machen per API Aufruf oder per Drag & Drop. Die fertigen Dokumente in WDS sehen dann zum Beispiel so aus:
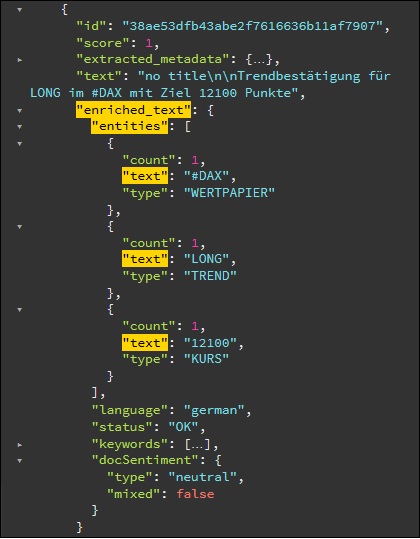
Das ist für erste Tests sinnvoll, später würde man das natürlich automatisieren um zum Beispiel alle relevanten Tweets automatisch über Watson Discovery Service verarbeiten.
Die Standard-Oberfläche in WDS ist für eine Auswertung aller Tweets nicht so wirklich hilfreich, sie ist nur als Beispiel zu verstehen, eigene Anpassungen sind in der Regel notwendig.
Man könnte sich zum Beispiel mit Hilfe der WDS API eine Oberfläche bauen welche den Verlauf der Trendaussagen zum DAX über die Zeit anzeigt. Alle Daten dazu wären in der WDS Collection enthalten, man muss lediglich das passende Frontend dazu entwickeln.
Wie geht es weiter?
Neben den beiden cloudbasierten Diensten gibt es auch die Möglichkeit das Textanalysemodell komplett „On Premise“ auf einer eigenen Infrastruktur laufen zu lassen.
Dazu existiert eine Standard WKS Integration in IBM Watson Explorer.
Im nächsten Beitrag dieser Serie beschreibe ich wie wir das trainierte Modell „On Premise“ im IBM Watson Explorer verwenden können.
… Ich bin gerade dabei diesen nächsten Beitrag zu verfassen, schau demnächst wieder vorbei, oder folge mir auf Twitter um den nächsten Beitrag nicht zu verpassen…