IBM Watson Knowledge Studio (WKS) bietet uns einen intuitiven Weg Expertenwissen vom Menschen auf eine Maschine zu übertragen.
Nach dem die Fachexperten die relevanten Begriffe und Zusammenhänge in den Trainingsdokumenten markiert haben können wir über Watson Knowledge Studio mit diesem Grundwissen ein Modell trainieren (überwachtes maschinelles Lernen / supervised machine learning).
Im diesem Artikel möchte ich beschreiben wie das maschinelle Lernen in WKS funktioniert und wie wir das trainierte Modell überprüfen und verbessern können.
Dies ist der vierte Teil meiner Artikelserie zum IBM Watson Knowledge Studio in Deutsch. Eine Einführung in WKS gibt es hier: Maschinelles Lernen in der Praxis: IBM Watson Knowledge Studio
Die Erstellung des Grundwissens für das Training habe ich hier beschrieben: Wissenstransfer vom Mensch zur Maschine mit IBM Watson Knowledge Studio
In der aktuellen Version von WKS wird während des maschinellen Lernens ein SIRE Modell trainiert. SIRE steht für „Statistical Information and Relation Extraction“ und wurde im IBM Research Lab entwickelt.
SIRE bietet uns eine natürlichsprachliche Verarbeitung von Texten. Ein SIRE Modell lernt anhand von verschiedenen linguistischen und statistischen Einflussgrößen Begriffe und Zusammenhänge aus Texten zu erkennen. Linguistische Einflussgrößen können zum Beispiel Wortarten oder Satzsyntax sein, als statische Einflussgrößen werden zum Beispiel Regressionsanalyseverfahren wie Maximum Entropy verwendet.
SIRE Modelle wurden bereits in unterschiedlichen Domänen erfolgreich angewendet, zum Beispiel für die Analyse von Nachrichten, von Unfallberichten oder im Gesundheitswesen.
Machine Learning Modell erstellen
Wenn wir ein Machine Learning Modell erstellen wählen wir zuerst das Dokumentenset aus das wir für das Training verwenden möchten. Da wir alle Dokumente bereits annotiert haben wählen wir hier „All“ aus und geben eine prozentuale Verteilung an zwischen Trainings-, Test- und Blindset.
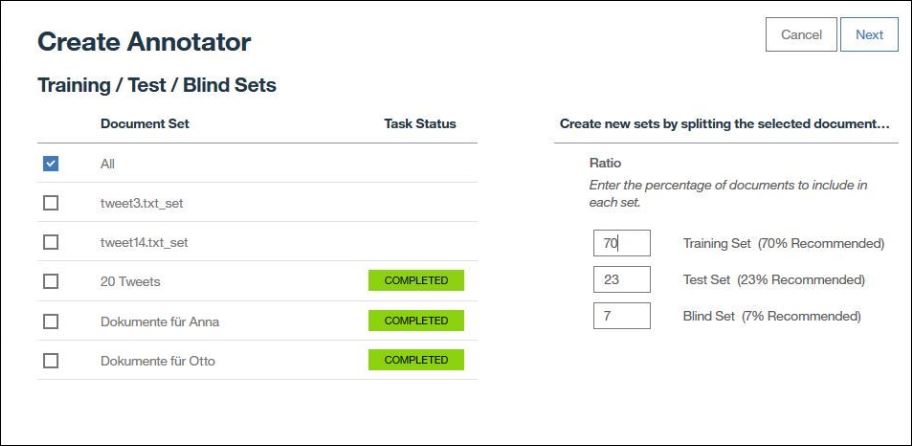
Das Trainingsset wird genutzt um das Modell zu trainieren. Im Standard werden 70% der Dokumente dem Trainingsset zugeordnet.
Das Testset wird genutzt um das Modell zu validieren. Werte wie Genauigkeit und Trefferquote des Modells werden auf Basis der Dokumente des Testsets berechnet. Für das Testset kann ich die Ergebnisse der automatischen Annotierung durch das Modell einsehen.
Durch die Prüfung der Annotationen im Einzelfall kann ich gezielt mein Typsystem, meine Annotationen oder die Annotationsrichtlinien verbessern. Im Standard werden 23% der Dokumente dem Testset zugeordnet.
Dokumente im Blindset werden weder für das Training noch für die Evaluierung verwendet, sondern um ein Overfitting (Überanpassung) des Modells zu verhindern.
Überanpassung beim maschinellen Lernen bedeutet das ich das Modell so optimiere das es zwar auf den Testdaten perfekt funktioniert, aber auf neuen Daten keine guten Ergebnisse mehr liefert.
Das Blindset erlaubt es mir mein Modell auf Basis des Dokumente des Testsets zu optimieren. Wenn ich dann einen Stand erreicht habe, der mir optimal erscheint, kann ich die „unverbrauchten“ Dokumente des Blindsets als Testset verwenden um zu prüfen ob ich auch auf unbekannten Dokumenten gute Ergebnisse erziele oder ob mein Modell nur überangepasst auf die Testdaten ist.
Im Standard werden 7% der Dokumente dem Blindset zugeordnet. Die Nutzung des Blindsets ist optional, ich kann hier auch 0 Prozent angeben wenn ich kein Blindset nutzen möchte.
Nach dem ich die gewünschten Prozentzahlen angegeben habe teilt Watson Knowledge Studio die Dokumente automatisch im angegebenen Verhältnis zwischen den drei Sets auf und startet mit Training und Evaluierung des Modells.
Überprüfung des Modells
Nach wenigen Minuten ist das erste Training abgeschlossen und wir können uns das Ergebnis anschauen um das Modell zu überprüfen.
Watson Knowledge Studio stellt uns dazu für die einzelnen Erwähnungstypen (Entität, Beziehung, Koreferenz) jeweils folgende Werte in einer Übersicht zur Verfügung:
- Precision (Präzision): Gibt die Wahrscheinlichkeit an mit der eine vom Modell gefundene Erwähnung relevant ist (Positiver Vorhersagewert).
- Recall (Trefferquote): Gibt die Wahrscheinlichkeit an mit der eine im Text enthaltene Erwähnung gefunden wird (Sensitivität).
- F1 Score (F1-Wert): Gibt den Mittelwert aus Genauigkeit und Trefferquote an. Der F1-Wert kombiniert die Precision (Genauigkeit) und Recall (Trefferquote) mittels des gewichteten harmonischen Mittels und wird als Orientierungswert für einen ersten Überblick verwendet.
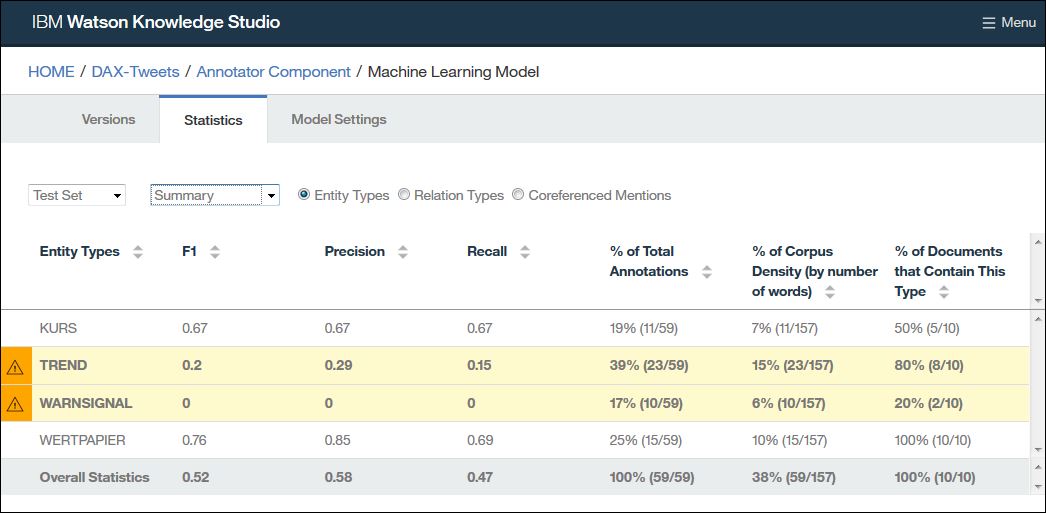
Das erste Trainingsergebnis für unser Beispielprojekt sieht noch sehr verbesserungsfähig aus:
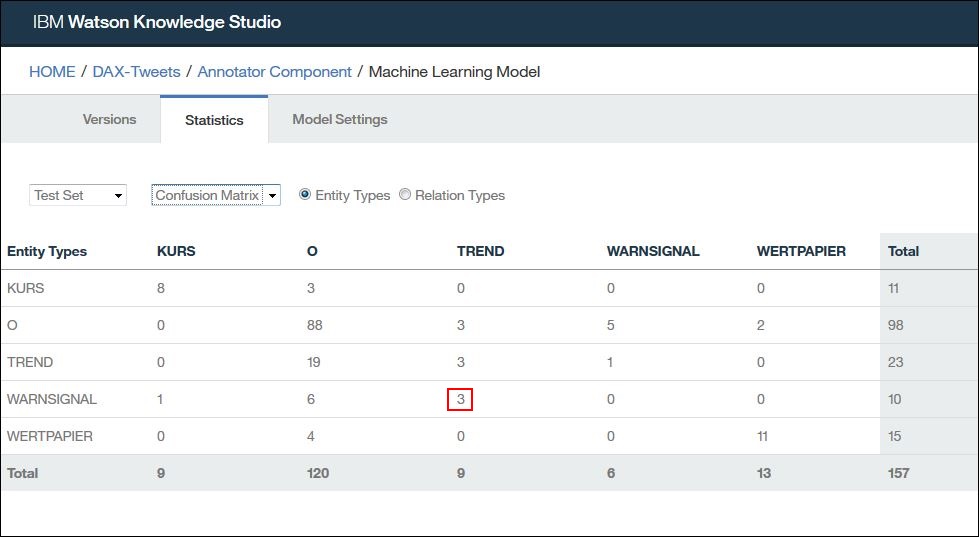
Neben der Übersichtsseite bietet uns Watson Knowledge Studio auch eine „Confusion Matrix“ (Wahrheitsmatrix) an, mit der ich vergleichen kann wie viele Entitäten jeweils richtig oder falsch zugeordnet wurden.
Bei Bedarf kann ich bis auf die Detailebene des einzelnen Dokuments heruntergehen um zu vergleichen was der Mensch und was die Maschine im Text annotiert hat.
Modell verbessern
Im ersten Schritt der Verbesserung des Modells betrachten wir nur die gefunden Entitäten.
Beziehungen und Koreferenzen hängen von den gefundenen Entitäten ab, daher ist es sinnvoll zuerst an der Erkennungsqualität der Entitäten zu arbeiten.
Aus der Auswertungsübersicht (siehe oben) sehen wir das die Entitäten „TREND“ und „WARNSIGNAL“ einen sehr schlechten F1-Wert haben.
Die Anzeige der „Confusion Matrix“ (Wahrheitsmatrix) zeigt uns das viele Entitäten die eigentlich „WARNSIGNAL“ sein sollten fälschlicherweise zu „TREND“ zugeordnet wurden:
Um das Problem mit dem Entitätstyp „WARNSIGNAL“ weiter zu durchdringen können wir für die Dokumente des Testsets vergleichen was vom Menschen und was von der Maschine annotiert wurde.
Als Beispiel für eine Falschannotierung finden wir den Satz „fällt unter die 10-Tage Linie“. Die menschlichen Annotierer haben „unter die 10-Tage Linie“ als Warnsignal annotiert (im Bild unten), die Maschine erkennt in „unter“ einen negativen Trend (im Bild oben).
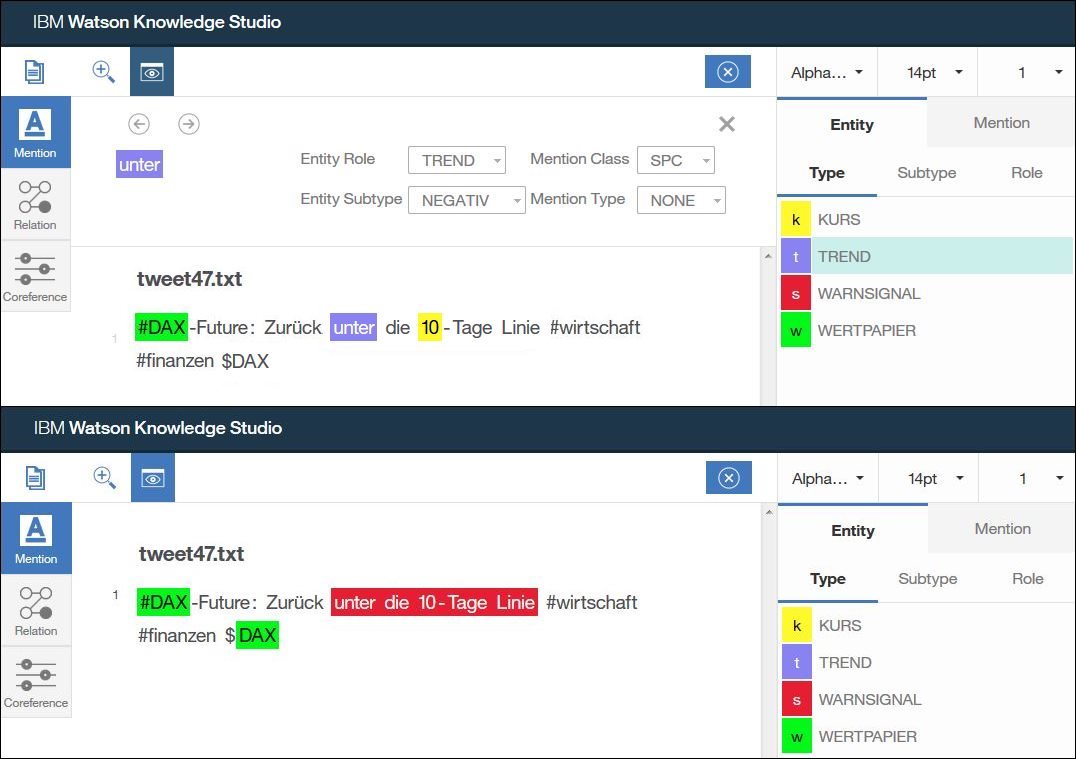
Beide Annotierungen sind an sich valide, was uns zu dem Schluss führt das unser Typsystem hier nicht ausreichend präzise ist. Eine der möglichen Lösungen für diesen Konflikt ist das wir „WARNSIGNAL“ aus dem Typsystem herausnehmen und definieren das die Annotierungen für negative Trends auch Warnsignale umfassen dürfen, sofern sie auch einen Trend beschreiben.
Eine weitere Erkenntnis aus der Auswertungsübersicht ist das die Entität „KURS“ ebenfalls noch Verbesserungspotential hat.
Durch Analyse der Dokumente sehen wir das Kurse häufig zusammen mit bestimmten Signalworten auftreten (bei 12.000 Punkten, ab 12.000, Stop Loss 12.000, usw.). Wir legen daher eine weitere Entität namens „SIGNALWORT_KURS“ im Typsystem an und annotieren damit diese Signalworte für Kurswerte in den Texten.
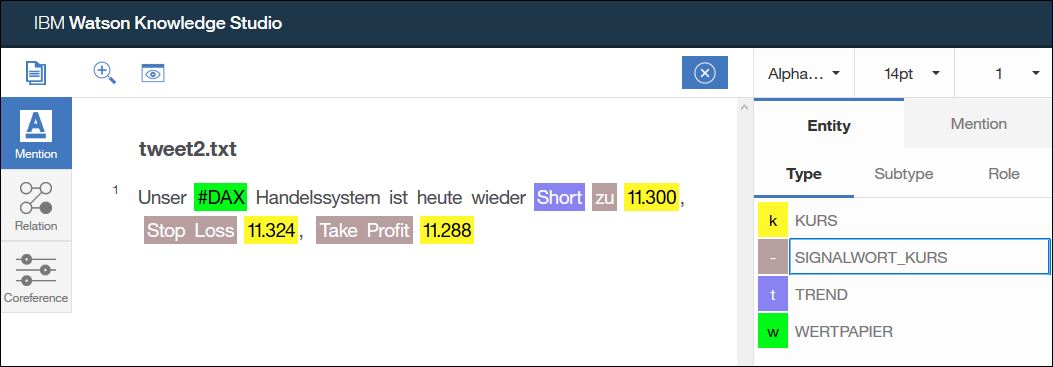
Nach dem die Dokumente mit den Veränderungen im Typsystem neu annotiert wurden sieht unsere Auswertung bereits wesentlich besser aus:
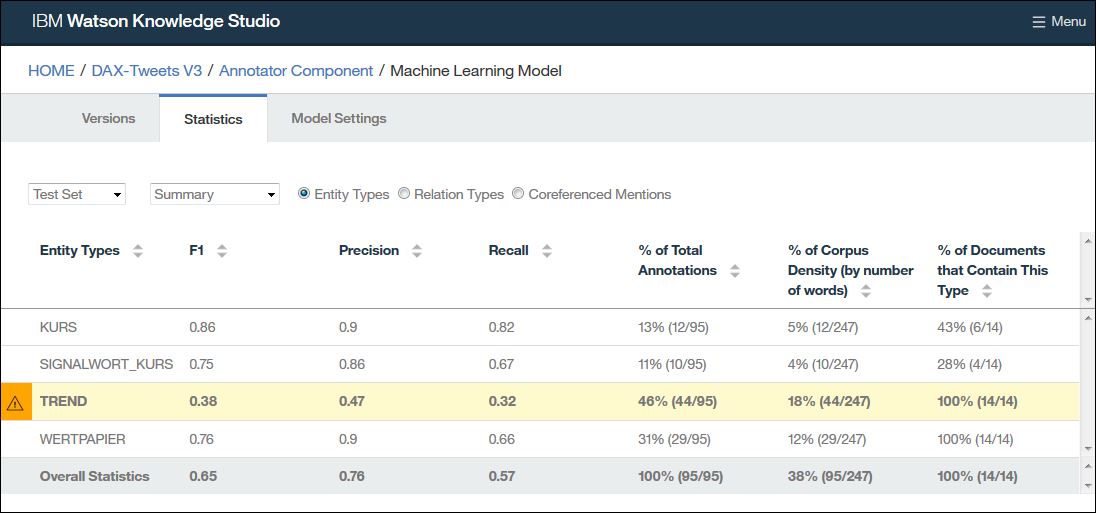
Um nun die Erkennungsrate für Trends weiter zu verbessern könnten wir das Wörterbuch „Trends“ erweitern und vor allem weitere relevante Beispiele für Trends finden, diese Annotieren und das Modell damit neu trainieren.
Die niedrigen Werte bei den Trefferquoten (Recall) sind auch allgemein ein Indikator dafür das wir zu wenig Trainingsdaten haben.
Die Dokumentation zu IBM Watson Knowledge Studio beschreibt in größerer Detailtiefe die notwendigen Schritte um ein Modell zu optimieren: Analyzing machine-learning model performance
Wörterbücher
Noch eine Klarstellung zu den Wörterbüchern. Diese können optional mit in das Training des Modells einfließen, jedoch darf man das nicht mit einem simplen Keyword Matching verwechseln!
Die Information „Steht im Wörterbuch“ ist einfach nur eine weitere Einflußgröße für unseren Algorithmus, aber bei weitem nicht der alleine entscheidende Faktor, wie es bei einem reinem Keyword Matching der Fall wäre.
Würde wir zum Beispiel „Siemens“ in unser Wörtbuch „Wertpapiere“ mit aufnehmen, würde das Modell im Text
„Siemens Bilanzpressekonferenz beginnt um 9 Uhr“
deswegen noch lange nicht „Siemens“ als Entität „WERTPAPIER“ erkennen, weil es auf solche Sätze nicht trainiert ist.
Allerdings erhöhen wir die Wahrscheinlichkeit das es im Satz
„Siemens wird heute freundlich erwartet“
richtigerweise „Siemens“ als Wertpapier erkennt, weil die Nennung dort in Zusammenhang mit einer Entität vom Typ „TREND“ erfolgt und unser Modell auf die Erkennung solcher Zusammenhänge trainiert ist.
Wie geht es weiter?
Hier noch ein paar weitere Informationen in Englisch zum Trainieren des Machine Learning Modells:
- Video: Watson Knowledge Studio Deep Dive – Train and Evaluate
- Video: Watson Knowledge Studio Getting Started – Annotator Component
- Watson Knowledge Studio – Training the machine-learning annotator
Unser fertig trainiertes Modell können wir nun in verschiedenen IBM Watson Diensten und Produkten einsetzen um dort unser domänenspezifisches Expertenwissen anzuwenden.
Dabei kann ich entweder cloudbasierte Dienste verwenden oder kann das Modell auch komplett „On Premise“ auf meiner eigenen Infrastruktur laufen lassen.
Im nächsten Beitrag dieser Serie beschreibe ich wie wir das trainierte Modell in den verschiedenen IBM Watson Diensten verwenden können: Eigene Machine Learning Textanalyse verwenden in IBM Watson