IBM Watson Knowledge Studio (WKS) bietet uns einen intuitiven Weg Expertenwissen vom Menschen auf eine Maschine zu übertragen.
Dieser Wissenstransfer findet statt in dem die Fachexperten in Beispieldokumenten die wichtigen Begriffe und Zusammenhänge markieren. Ähnlich wie wenn man mit einem Textmarker durch einen Text geht und die wichtigen Stellen farblich hervorhebt. In WKS wird dieser Schritt „Human Annotation“ genannt.
Ergebnis dieser Annotationen ist das sogenannte „Ground Truth“, das Grund- oder Basiswissen für unser System.
Mit diesem Grundwissen wird dann ein Modell trainiert (überwachtes maschinelles Lernen / supervised machine learning). Das System lernt die wichtigen Begriffe und ihre Zusammenhänge im Text zu erkennen und kann dieses gelernte Wissen dann auf neue, unbekannte Texte anwenden.
In diesem Artikel beschreibe ich wie wir in Watson Knowledge Studio dieses Grundwissen für unser System erstellen können.
Dies ist der dritte Teil meiner Artikelserie zum IBM Watson Knowledge Studio in Deutsch. Eine Einführung in WKS gibt es hier: Maschinelles Lernen in der Praxis: IBM Watson Knowledge Studio
Voraussetzungen
Bevor wir mit der Annotierung beginnen können müssen wir zuerst ein Typsystem für unseren Anwendungsfall definiert haben. In „Entwurf eines Typsystems in IBM Watson Knowledge Studio“ habe ich die Grundlagen dafür sowie ein Typsystem für unser Beispielprojekt „DAX Tweets“ beschrieben.
Danach gilt es geeignete Beispieldokumente zu finden und diese hochzuladen. Für die Annotierung und das Training brauchen wir Textdokumente im UTF-8 Format. Das ist besonders für deutsche Sonderzeichen sehr wichtig weil diese sonst falsch dargestellt werden. Eine Konvertierung von vorhandenen Textdokumenten nach UTF-8 kann zum Beispiel über den Notepad++ Editor erfolgen.
Wie viele Dokumente benötige ich denn nun für ein Training?
Diese Frage lässt sich so allgemein leider nicht beantworten, es kommt vor allem auf die Anzahl an Entitäts- und Beziehungstypen an die ich finden möchte. Als Richtwert sollten für jede Erwähnung (Entität oder Beziehung) ungefähr 50 Beispiele zur Verfügung stehen. Dabei können natürlich in jedem Dokument mehrere Beispiele für die unterschiedlichen Erwähnungen enthalten sein.
- In der ersten Iteration starten wir mit höchstens 10 Dokumenten. Jeder Beteiligte annotiert dabei alle diese Dokumente. Durch Vergleich dieser ersten Annotationen können wir feststellen wo es noch Klärungsbedarf im Typsystem oder Verbesserungsbedarf bei den Annotationsregeln gibt.
- In der zweiten Iteration bearbeiten wir ca. 50 Dokumente, diese werden zur Qualitätssicherung meist mit 20% Überschneidung unter den Beteiligten aufgeteilt, dazu später mehr. Ein Modell das mit 50 Dokumenten trainiert wurde ist meistens für einen „Proof of Concept“ schon hinreichend gut.
- In den weiteren Iterationen werden gezielt die Entitäten und Relationen verbessert die noch eine geringe Qualität in der Textanalyse zeigen. Die Anzahl der dazu notwendigen Dokumente variiert sehr stark, aber das weitere 100 Dokumente annotiert werden müssen ist nicht ungewöhnlich.
Vorannotierung
Das manuelle Annotieren von Texten ist eine recht zeitaufwendige Angelegenheit für die Fachexperten. Um dies zu beschleunigen bietet uns WKS ein paar gute Möglichkeiten mit denen wir die Trainingsdokumente bereits vorab automatisch annotieren können:
- Wörterbücher / Dictionaries: Werden in der Regel genutzt um eigene, domänenspezifische Wörter in den Texten vorab zu annotieren. In unserem Beispielprojekt könnten wir alle Wörter die Trends beschreiben, wie „Aufwärtstrend“, „nach unten“, usw. über Wörterbücher markieren lassen.
- Regeln / Rules: Über Regeln kann ich sowohl Wörterbücher, feste Zeichenfolgen und häufig auftretende Wortfolgen vorab annotieren. In unserem Beispielprojekt könnten wir die Kursangaben für den DAX Kurs (wie „11.234“) über einen regulären Ausdruck markieren lassen sowie alle Wörter die Trends beschreiben über Wörterbücher.
- Alchemy Language: Über die Alchemy Language können wir interessante Begriffe wie Personen, Organisationen, Länder, usw. in den Texten vorab annotieren. Wenn wir in unserem Beispielprojekt nicht nur DAX Tweets sondern auch Tweets zu anderen börsennotierten Unternehmen analysieren möchten könnten wir hiermit die Firmennamen markieren lassen.
- Eigene Modelle: Wenn ich bereits eigenen Modelle mit meinem Fachwissen trainiert habe kann ich diese wiederum nutzen um in neuen Projekten die Dokumente damit vorab zu annotieren. Das ist natürlich insbesondere dann interessant wenn das neue Projekt ähnliche Inhalte hat wie das bereits existierende Projekt.
- Import von Watson Explorer: Wenn ich IBM Watson Explorer im Einsatz habe und dort bereits Wörterbücher und semantische Regeln für die Textanalyse nutze kann ich meine Trainingsdokumente dort analysieren, das Ergebnis der Analyse exportieren und damit die Trainingsdokumente vorab annotieren.
Bei den Optionen zur Vorannotierung ist es wichtig zu verstehen das diese nur dazu genutzt werden um die Beispieltexte für das maschinelle Lernen schneller bereitstellen zu können, für das trainierte Modell später aber nicht mehr notwendig sind.
Das Modell selbst lernt exklusiv auf Basis dieser Beispieltexte, allerdings können die definierten Wörterbücher optional mit in dieses Lernen einfließen um die Präzision des Modells weiter zu verbessern.
Es macht daher nichts wenn bestimmte Wörter nicht in den Wörterbüchern enthalten oder bestimmte Kombinationen in den Regeln nicht erfasst sind. Solange die Beispieltexte vom Menschen richtig annotiert werden wird das Modell trotzdem lernen diese Begriffe als relevant zu erkennen. Diese Unabhängigkeit von vorgegebenen Wörterbüchern und Regeln ist ja gerade eine der Stärken des maschinellen Lernens mit Watson Knowledge Studios.
Für unser Beispielprojekt habe ich mich für eine regelbasierte Vorannotierung entschieden weil wir damit einfach Wörterbücher (für Wertpapier und Trend) mit regulären Ausdrücken (für Kurswerte) kombinieren können.
Die Erstellung dieser Regeln findet in einem eigenen Regeleditor statt, den ich gerne in einem separaten Artikel beschreiben möchte.
Das Vorannotieren selbst ist dann sehr einfach, den Annotator „Rule“ auswählen, definieren welche Wörterbücher oder Regeln welche Entitätstypen erzeugen sollen (sog. „Class Mapping“), die zu annotierenden Dokumente auswählen und los gehts.
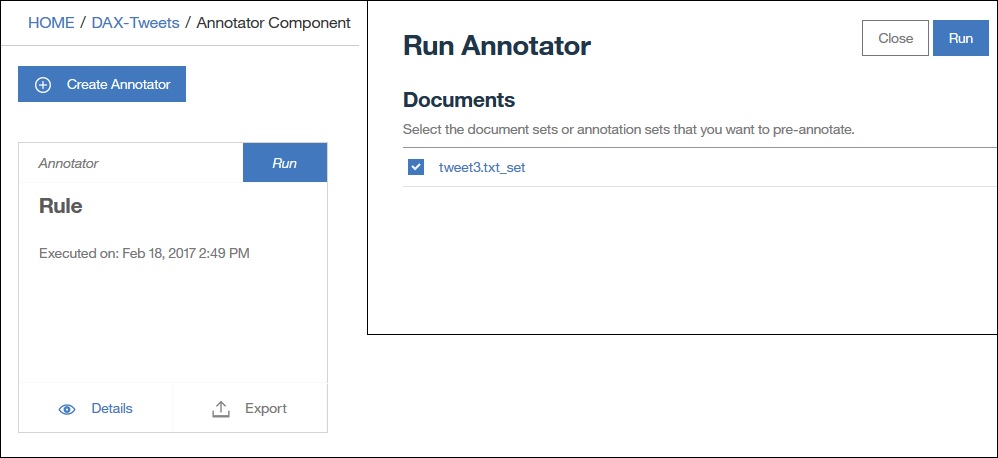
Annotationssets und Aufgaben
Der nächste Schritt ist das Aufteilen der Dokumente in Annotationssets (Annotation Sets).
Wir erstellen pro Person ein eigenes Annotationsset mit einer prozentualen Überschneidung der Dokumente in den Sets. Manche Dokument sind also in mehreren Sets enthalten und werden dadurch von mehreren Personen annotiert. Anhand dieser überlappenden Dokumente kann ich später im Sinne einer Qualitätssicherung prüfen ob identisch annotiert wurde oder ob hier eventuell noch Unklarheiten vorliegen bezüglich den Annotationsrichtlinien.
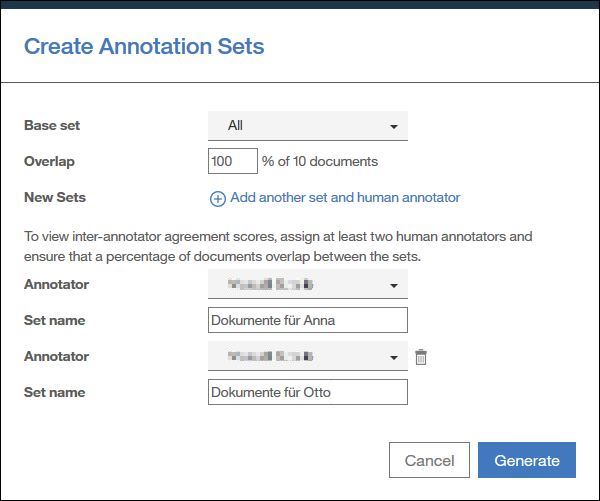
In diesem Beispiel legen wir zwei Sets an, „Dokumente für Anna“ und „Dokumente für Otto“. Es ist die erste Iteration, wir arbeiten daher erst mal nur mit 10 Dokumenten und 100% Überschneidung. Dadurch bekommen beide Benutzer die gleichen Dokumente zum Annotieren, wir können später prüfen ob beide identisch arbeiten bevor wir größere Annotationssets angehen.
Anschließend legen wir eine Aufgabe (Task) an mit dem Namen „Erste Iteration“ und ordnen beide Sets dieser Aufgabe zu. Die Aufgabe ist unsere Klammer über die wir später zum Beispiel auch den Vergleich der Annotationen bewerkstelligen können.
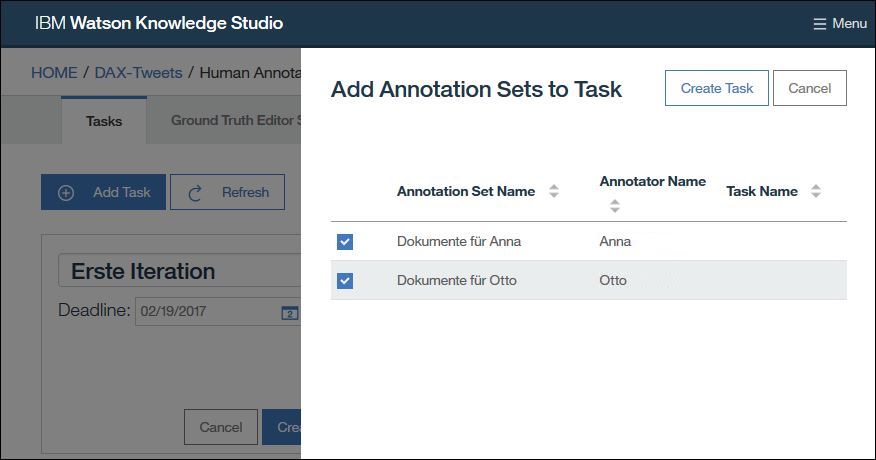
Human Annotation
Nun da jeder Beteiligte seine Aufgaben hat kann es an die wirkliche Arbeit gehen.
Bisher haben wir alle Einstellungen in der Rolle „Administrator“ erledigt. Watson Knowledge Studio bietet darüber hinaus eine weitere Rolle „Human Annotator“ (menschlicher Annotierer) an. Benutzer mit dieser Rolle bekommen Dokumentensets zugewiesen und können diese Annotieren.
Als Benutzer mit der „Human Annotator“ Rolle sehe ich nach der Anmeldung jeweils nur meine eigenen Aufgaben und Dokumente. ich kann eine der Aufgaben öffnen und gelangen dadurch auf die Liste der von mir zu bearbeitenden Dokumente.
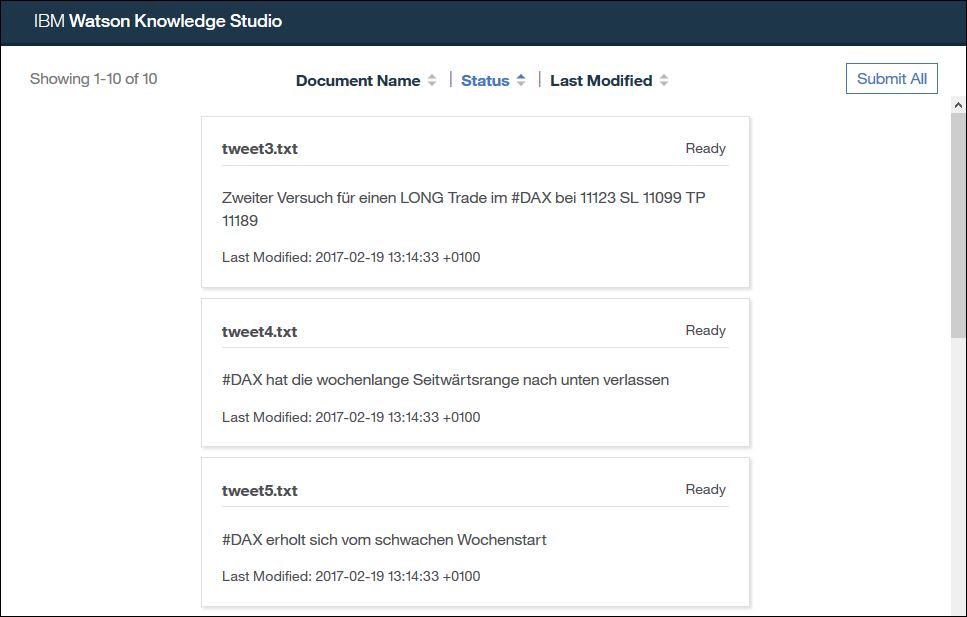
Mit einem Klick auf eines der Dokumente komme ich in die Annotationsansicht.
In der Regel gehen wir beim Annotieren so vor das wir:
- zuerst alle Entitäten im Text markieren,
- danach alle Koreferenzen markieren,
- zum Schluss alle Beziehungen markieren.
Nach dem ich das Dokument geöffnet habe sehe ich die von der Vorannotierung bereits automatisch angebrachten Markierungen.
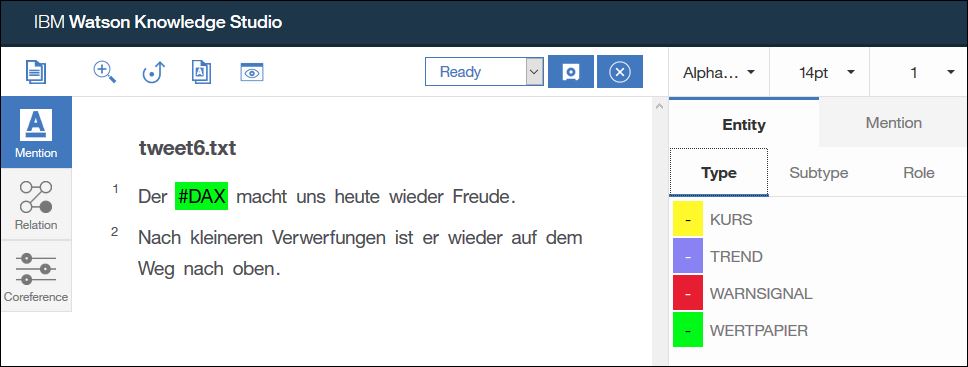
Ich markiere nun die weiteren Entitäten die ich erkenne. Dazu stelle ich zuerst sicher das in der linken Seitenleiste „Mention“ (Erwähnung) ausgewählt ist.
In unserem Beispiel beschreibt „nach oben“ einen Trend, daher markiere ich diese beiden Worte und wähle den Typ „TREND“ aus, sowie als Untertyp „POSITIV“.
Außerdem ist „er“ eine weitere Erwähnung von DAX, daher markiere ich dieses Wort und wähle den Typ „WERTPAPIER“ aus. Ein Untertyp ist für diese Entität nicht definiert und muss daher auch nicht ausgewählt werden.
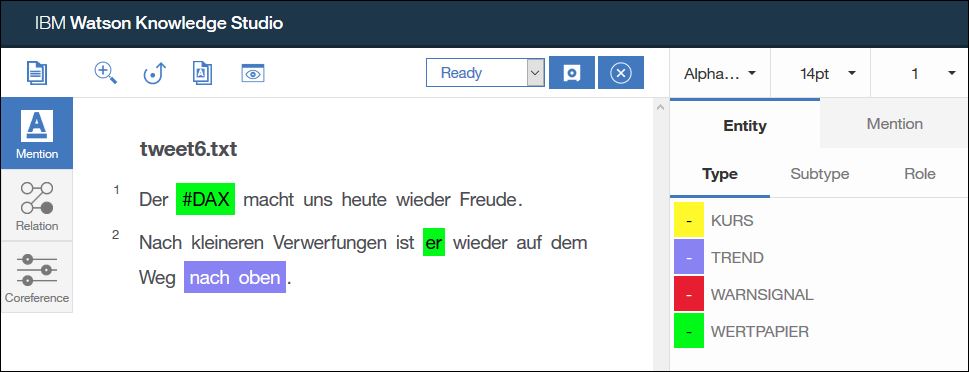
Damit habe ich die Markierung der Entitäten abgeschlossen und klicke nun in der Seitenleiste links auf „Coreference“ (Koreferenz).
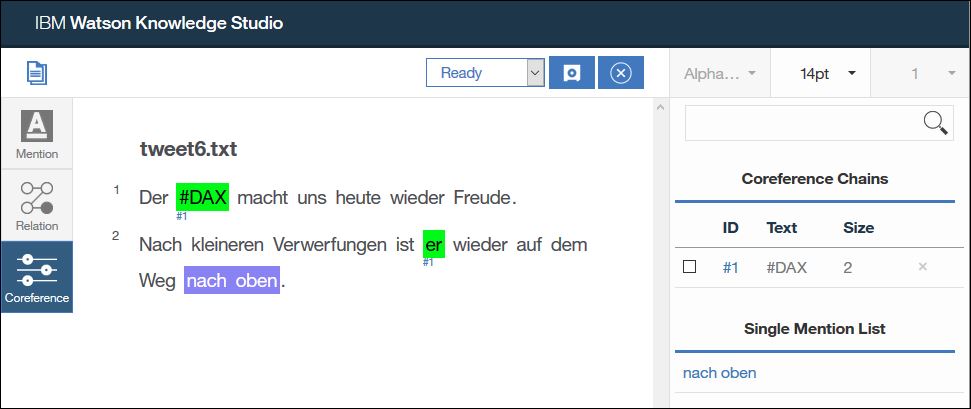
„DAX“ und „er“ beziehen sich auf die selbe Sache, daher klicke ich beide Entitäten an. Die Reihenfolge welche ich zuerst anklicke ist dabei egal. Durch einen Doppelklick auf die letzte Entität wird einen Koreferenzkette erzeugt. Alle Koreferenzketten werden in der rechten Seitenleiste gelistet, dort kann ich auch weitere Entitäten in die Kette dazunehmen oder aus der Kette entfernen.
Als letzten Schritt wähle ich „Relation“ (Beziehung) in der linken Seitenleiste aus um die Beziehungen zu markieren.
Der Trend „nach oben“ bezieht sich auf den DAX. Beziehungen kann ich aber nur innerhalb eines Satzes festlegen, daher kann ich keine Beziehung direkt von „nach oben“ zu „DAX“ ziehen. Allerdings habe ich ja das Wort „er“ im Satz, das ja ebenfalls den DAX bezeichnet.
Um die Beziehung festzulegen klicke ich zuerst auf „nach oben“ (TREND), dann auf „er“ (WERTPAPIER). In der rechten Seitenleiste werden mir nun die gültigen Beziehungstypen für diese Kombination von Entitäten angezeigt, hier nur „TrendZu“.
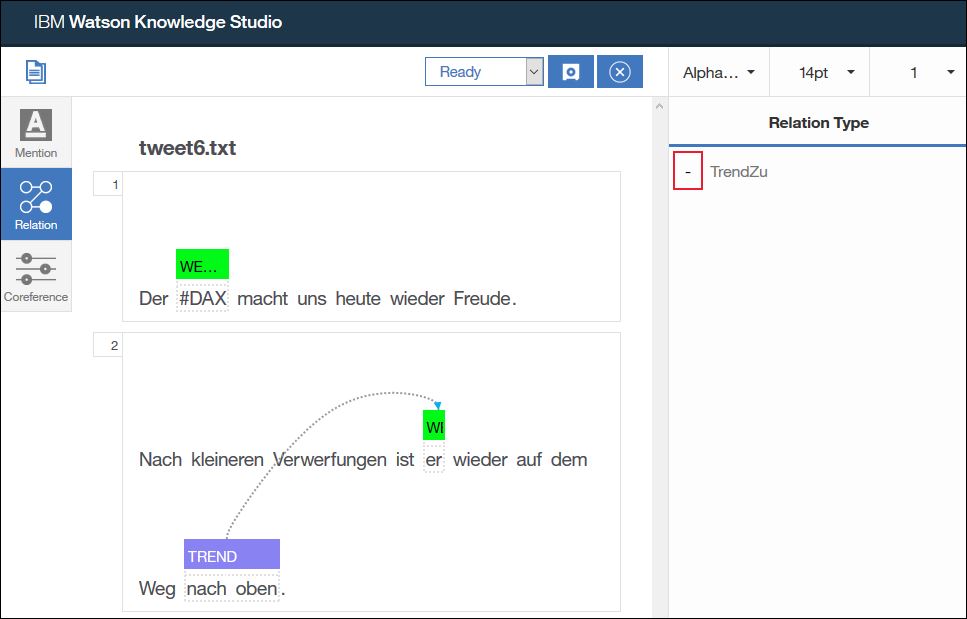
Ich klicke rechts auf den Beziehungstyp „TrendZu“, dadurch wird die Beziehung in das Dokument eingetragen.
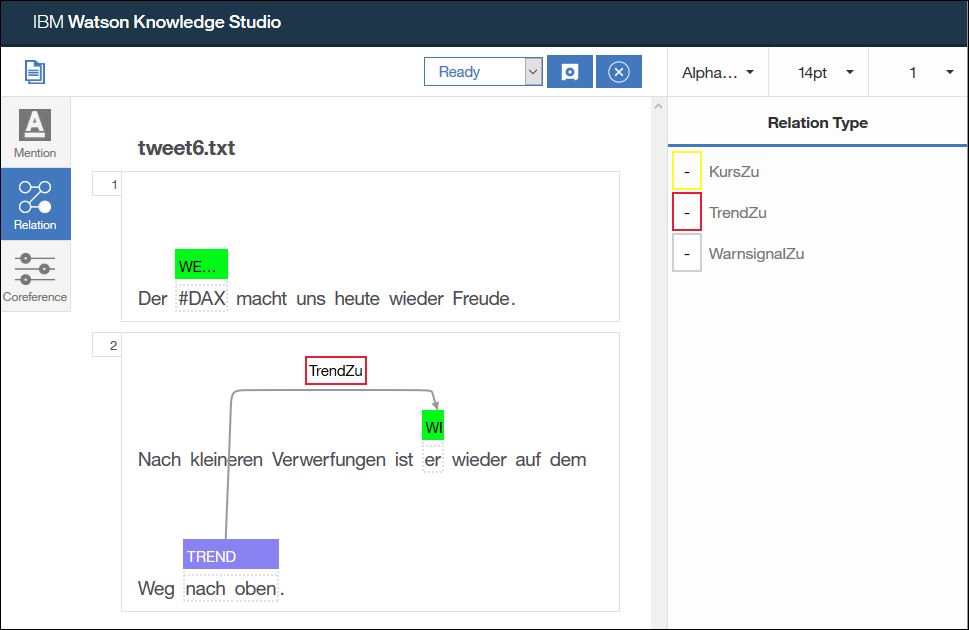
Damit habe ich das Dokument fertig annotiert. Alle Erwähnungen, Koreferenzen und Beziehungen sind markiert. Ich kann nun oben auf die „Save“ Schaltfläche klicken um meinen Arbeit zu speichern. Solange das Dokument im Status „In Progress“ ist kann ich jederzeit zurückkehren um die Annotationen noch mal zu ändern.
Ist die Arbeit an dem Dokument abgeschlossen kann ich aus der Auswahlliste oben auch „Completed“ auswählen.
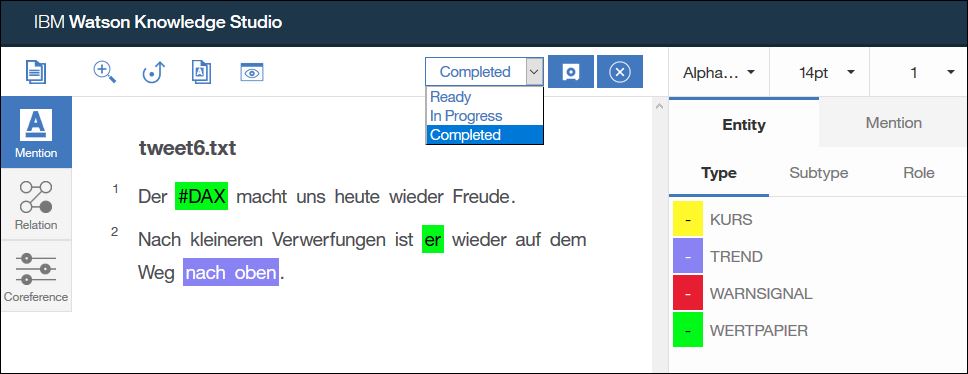
Aber Vorsicht: Dadurch wird das Dokument für die Bearbeitung gesperrt. Wenn ich später doch noch etwas korrigieren möchte dann kann ich es als Annotator nicht mehr selbst entsperren sondern muss mich an den Administrator wenden.
Aus diesem Grund markieren wir in der Regel erst dann Dokumente als „Completed“ wenn wir unser gesamtes Set durchgearbeitet haben und sicher sind das wir keine Änderungen mehr vornehmen müssen.
Mit einem Klick auf die „Close“ Schaltfläche schließe ich das Dokument und komme wieder in die Dokumentenliste zurück und kann mit dem nächsten Dokument weitermachen.
Best Practices
Hier noch ein paar Best Practices für die „Human Annotation“:
- Zuerst Entitäten, dann Koreferenzen, dann Beziehungen markieren (Ausnahme sind sehr lange Dokumente, da kann man auch absatzweise arbeiten).
- Immer mindestens ein ganzes Wort markieren, keine Wortteile.
- So wenig Worte wie möglich, aber so viele wie nötig, annotieren.
- Keine überlappenden Annotationen anbringen.
- Zwei Entitäten sind entweder eine Koreferenz oder haben eine Beziehung zueinander, niemals beides gleichzeitig.
- Speichern nicht vergessen!
- Wenn man sich komplett verannotiert hat: STRG+Z macht die letzten Schritte rückgängig, Dokument schließen ohne Speichern verwirft alle Änderungen seit dem letzten Speichern.
- Tastaturkürzel können die Arbeit erheblich vereinfachen. Am besten eine Liste der Tastaturkürzel anlegen und den Annotatoren zur Verfügung stellen.
- Dokumente werden erst auf „Completed“ gesetzt wenn ich mir sicher bin das es keine Änderungen mehr gibt.
- Alle Beteiligten sollten sich vorher mindestens die User Guides angeschaut haben. Besser ist es eine gemeinsame Trainingsession einzuplanen.
- Dokumente immer komplett annotieren, der Algorithmus lernt auch von negativen Beispielen, also wenn Dinge nicht annotiert sind. Daher sollte alles annotiert sein was annotiert werden muss.
- Konsistent arbeiten, Unklarheiten aufschreiben und im Team besprechen.
- Während die Experten annotieren lässt der Administrator seine Finger vom System. Es werden keine Typsystemänderungen gemacht, neue Dokumente hochgeladen oder sonstiger Unfug getrieben.
- Erweiterungen der Wörterbücher sollen von den Fachexperten aktiv vorgeschlagen werden. Bessere Wörterbücher helfen bei der nächsten Iteration neue Dokumente noch besser vorab zu annotieren. Bitte aber während die Annotation läuft keine Vorannotierung durchführen.
- Nach jeder abgeschlossenen Iteration wird ein komplettes Backup des aktuellen Stands gemacht (Typsystem, Wörterbücher, annotierte Dokumente, Regeln, trainierte Modelle, usw.).
Dokumente entsperren
Dokumente die zu früh auf „Completed“ gesetzt wurden kann der Administrator folgendermaßen entsperren:
- Task öffnen.
- Set öffnen das die Dokumente enthält.
- Über „Submit All“ alle Dokumente auf „Completed“ setzen.
- In Task auf „Refresh“ klicken. Status für das Set ist nun „Submitted“.
- Set auswählen und über „Reject“ zurückweisen.
- Nun sind wieder alle Dokumente im Status „In Process“.
Qualitätssicherung
Nach dem alle Experten ihre Arbeit an den Dokumenten beendet haben wird es Zeit die Qualität der Annotationen sicherzustellen.
Dies ist ein wichtiger Schritt da hiermit die Qualität des Grundwissens für das maschinelle Lernen sichergestellt wird. Wird hier zu lax verfahren stehen dem System keine eindeutigen Lerndaten zur Verfügung.
Inter-Annotator Agreement
Eine erste Information über die Qualität der Annotationen gibt uns das „Inter-Annotator Agreement“. Das ist ein Wert zwischen 0 und 1 der die Übereinstimmung der Annotationen angibt. Je näher dieser Wert an 1 ist desto besser.
Welcher Mindestwert hier noch akzeptabel ist hängt sehr stark von der Komplexität des Typsystem und der Domäne ab. Die Vorgaben aus dem KLUE Typsystem für Nachrichten empfehlen als Mindestwerte:
- Erwähnungen/Entitäten (Mentions): 0,85
- Beziehungen (Relations): 0,8
- Koreferenzen (Co-references): 0,9
Da das „Inter-Annotator Agreement“ auf Basis aller überlappenden Dokumente der Sets einer Aufgabe berechnet wird ist eine endgültige Auswertung erst sinnvoll wenn alle Dokumente in allen Sets annotiert wurden.
Zuerst betrachten wir die Auswertung nach Paaren. Dadurch bekommen wir einen Gesamtwert für alle Entitäten, Beziehungen und Koreferenzen und zusätzlich eine Auswertung die jeweils zwei Annotierer miteinander vergleicht.
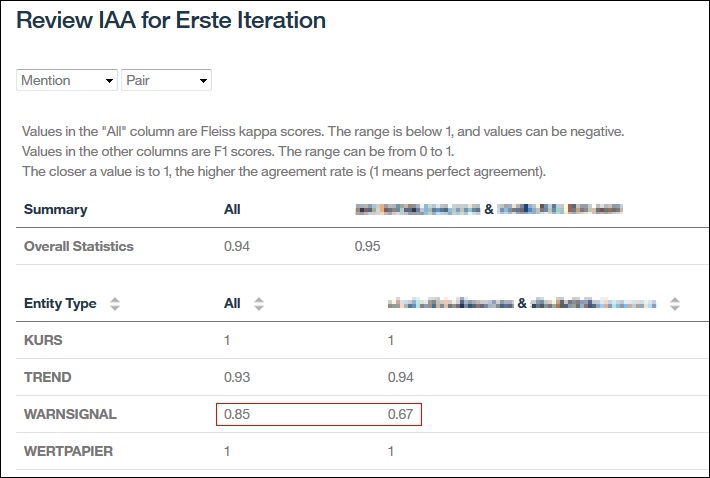
Ist der Gesamtwert für bestimmte Entitäten oder Beziehungen zu schlecht, insbesondere über alle Paarvergleiche hinweg, dann ist das ein Hinweis darauf das mein Typsystem oder die Annotationsregeln hier nicht eindeutig sind.
Hat ein bestimmter Annotierer generell über alle Paarvergleiche einen schlechteren Wert als sein Partner dann kann das ein Hinweis darauf sein das wir ihn noch mal gezielt schulen müssen.
In unserem Beispiel oben sehen wir das die Ergebnisse für die Entitäten „KURS“ und „WERTPAPIER“ perfekt sind und für „TREND“ akzeptabel. Für die Entität „WARNSIGNAL“ dagegen müssen wir noch mal nacharbeiten.
Wir können nun auf die Ansicht „Document“ wechseln, zwei Annotierer auswählen und sehen genau in welchen Dokumenten sie unterschiedlich annotiert haben. Der Wert 1 bedeutet hier wieder volle Übereinstimmung, 0 bedeutet keine Übereinstimmung, N/A bedeutet das dieser Entitätstyp nicht im Dokument verwendet wurde.
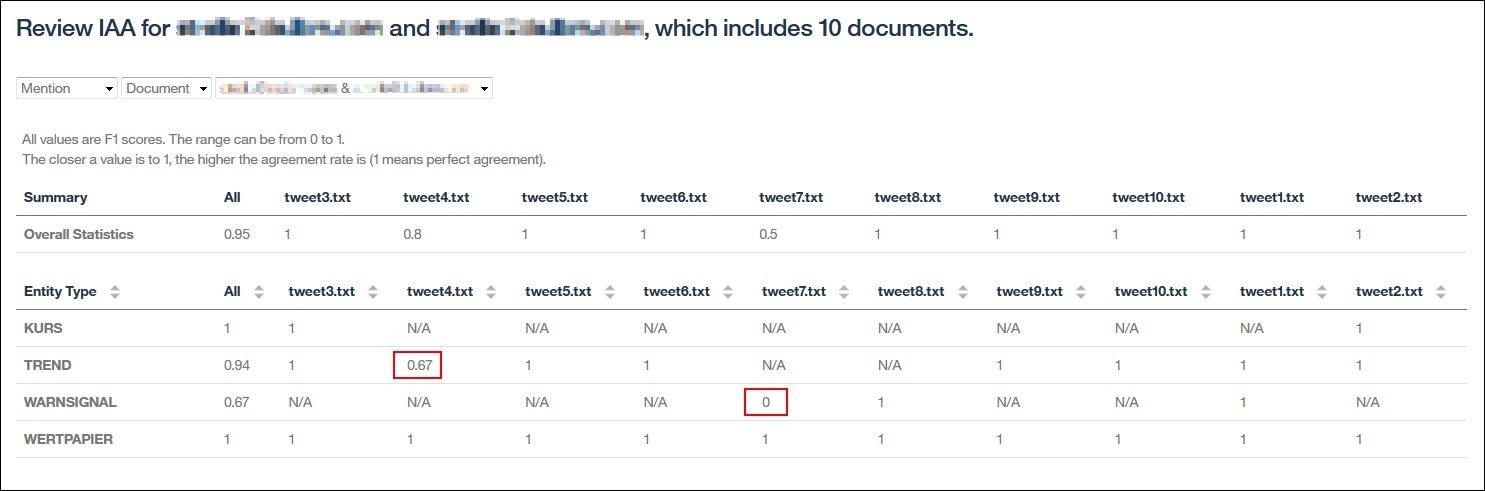
Für „WARNSIGNAL“ sehen wir im Dokument „tweet7.txt“ eine Übereinstimmung von 0, das bedeutet das wir gezielt in diesem Dokument prüfen müssen wo die Unklarheit herkommt.
Außerdem würde ich hier auch noch die Markierungen für „TREND“ im Dokument „tweet4.txt“ überprüfen da die Übereinstimmung hier nur 0,67 beträgt.
Diese Auswertung führen wir ebenfalls für die Beziehungen und die Koreferenzen durch.
Idealerweise sollte man die ersten Auswertungen zusammen im Team durchführen. Dann aber bitte darauf achten das alle fair miteinander umgehen. Bei unterschiedlichen Annotationen ist erst mal entweder das Typsystem zu komplex oder die Annotationsregeln nicht eindeutig genug. Grundsätzlich gehen wir davon aus das jeder Annotierer sein Bestes gegeben hat und greifen in der Diskussion der Markierungen niemanden persönlich an.
Nach dem die Konflikte besprochen und geklärt sind haben wir als Administrator zwei Möglichkeiten.
Wir können die jeweiligen Sets zurückweisen („Reject“), dadurch haben die Eigentümer der Sets die Möglichkeit die Markierungen selbst zu korrigieren. Das ist im Sinne eines Lerneffekts meistens die bessere Alternative.
Adjudication / Beurteilung
Alternativ kann es bei größeren Dokumentensets oder kleineren Änderungen auch sinnvoll sein das der Administrator bzw. ein Fachexperte die Konflikte selbst auflöst. Dieser Prozess nennt sich in WKS „Adjudication“ (Beurteilung).
Damit die Adjudication-Schaltfläche „Check Overlapping Documents for Conflicts“ aktiv wird muss ich beide Annotationssets gemeinsam markieren und gleichzeitig akzeptieren.
Wenn es in den überlappenden Dokumenten Konflikte gibt wird der Status damit auf „IN CONFLICT“ geändert und ich kann das Adjudication Tool nutzen um diese Konflikte auszuräumen.
Zuerst sehe ich eine Liste aller überlappender Dokumente. Ich kann jedes Dokument aus der Liste akzeptieren in dem ich den „Accept“ Link betätige und mich für eine der Versionen entscheide.
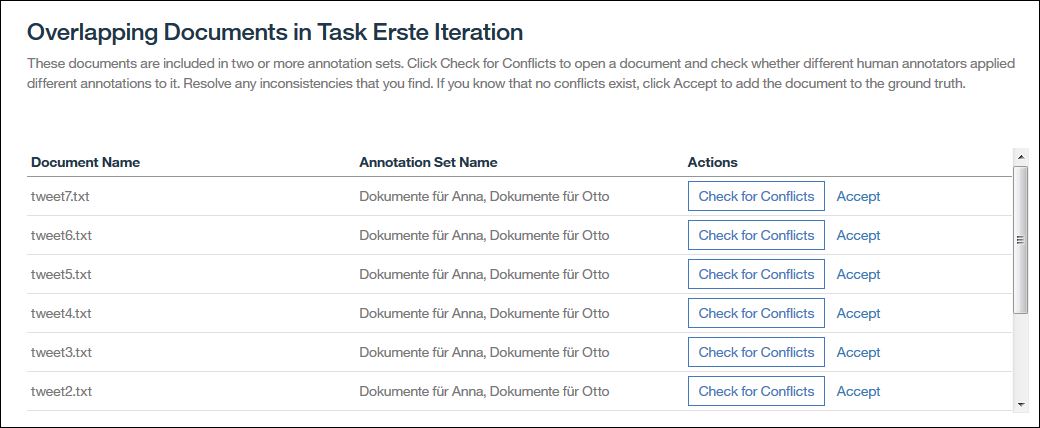
In der Regel sollte man aber über „Check for Conflicts“ die Unterschiede anzeigen und ausräumen.
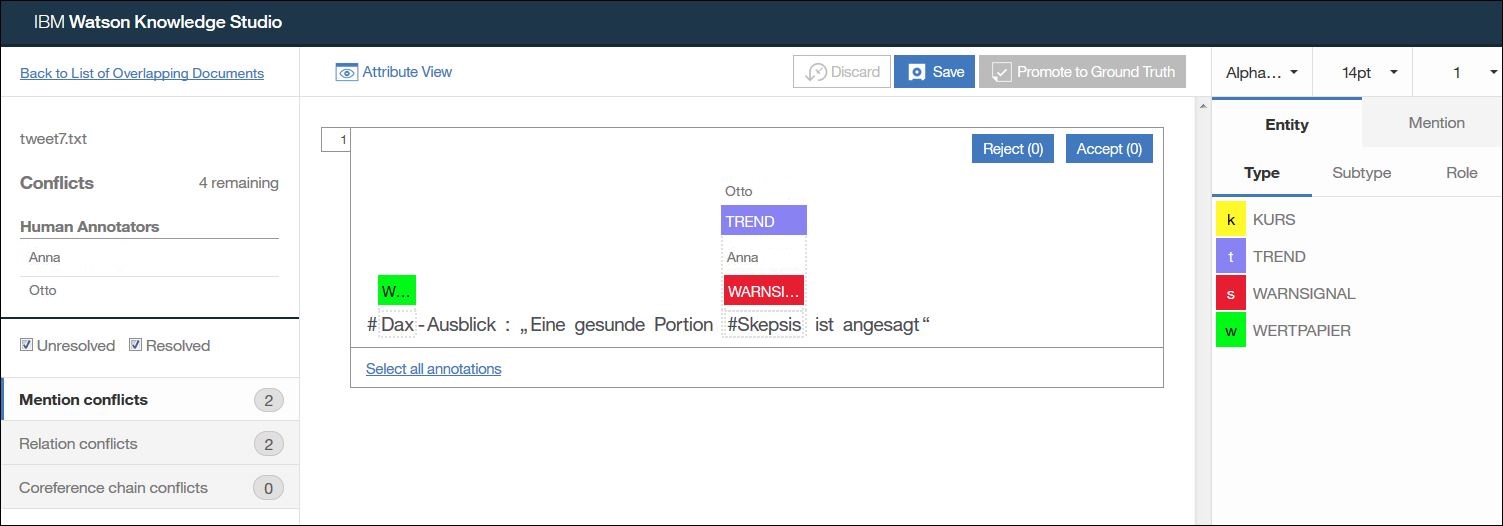
In diesem Beispiel sehe ich das es zwei Konflikte gibt, jeweils bei den Erwähnungen und den Beziehungen. Die Benutzerin Anna hat das hier Wort „Skepsis“ als „WARNSIGNAL“ annotiert, Otto als „TREND“.
Richtig ist gemäß den Annotationsregeln der Entitätstyp „WARNSIGNAL“. Deswegen markiere ich die Annotation „TREND“ und klicke auf „Reject“.
In diesem Video wird das Adjudication Tool noch mal im Detail gezeigt:
Nach dem ich auf diese Weise alle Konflikte aufgelöst habe kann ich über „Promote to Ground Truth“ das jetzt korrigierte Dokument in das Basiswissen übergeben.
Wie geht es weiter?
Nun da wir unser Grund- oder Basiswissen erstellt haben sollten wir es nutzen um damit mittels maschinellem Lernen ein Modell zu trainieren.
Zur Vertiefung aber erst mal noch ein paar weitere Informationen in Englisch:
- Video: Watson Knowledge Studio Deep Dive – Training Corpus
- Video: Watson Knowledge Studio Deep Dive – Dictionaries
- Video: Watson Knowledge Studio Deep Dive – Human Annotation
- Video: Watson Knowledge Studio Deep Dive – Ground Truth Creation
Im nächsten Beitrag dieser Serie beschreibe ich wie wir das Grundwissen für das maschinelle Lernen nutzen und wie wir das trainierte Modell prüfen und verbessern können: Machine Learning Modell trainieren mit Watson Knowledge Studio