Der erste Schritt in einem Textanalyseprojekt mit IBM Watson Knowledge Studio (WKS) sollte der Entwurf eines Typsystems sein.
Das Typsystem beschreibt welche Begriffe (Entitäten) und welche Zusammenhänge (Relationen) später durch das trainierte Modell aus dem Text extrahiert werden sollen.
Eine der grundlegenden Voraussetzungen um ein Typsystem zu entwerfen ist es die fachliche Domäne und das Geschäftsproblem des Kunden zu verstehen.
Daher sind am Anfang eines WKS Projektes in Zusammenarbeit mit dem Kunden ein paar grundlegende Fragen zu klären:
- Welche Informationen sollen aus den Texten extrahiert werden?
- Können diese Informationen dazu beitragen das Geschäftsproblem des Kunden zu lösen?
- Sind diese Informationen überhaupt in den zu analysierenden Texten enthalten?
- Kann eine ausreichende Anzahl von relevanten Beispieltexten für das Training bereitgestellt werden?
Dies ist der zweite Teil meiner Artikelserie zum IBM Watson Knowledge Studio in Deutsch. Eine Einführung in WKS gibt es hier: Maschinelles Lernen in der Praxis: IBM Watson Knowledge Studio
Erst nach dem diese fachlichen Fragen geklärt sind sollte man damit beginnen ein Typsystem zu entwerfen.
Best Practice ist das man für den Entwurf des Typsystems genügend Zeit einplant. Großflächige Änderungen im Nachhinein können einen enormen zusätzlichem Aufwand verursachen, wenn zum Beispiel bereits annotierte Trainingsdokumente neu annotiert werden müssen. Das können wir durch eine sorgfältige Planung des Typsystems weitgehend vermeiden.
Für welche Domäne sollen wir nun hier unser Beispiel-Typsystem entwerfen? Ich habe lange darüber nachgedacht, aber keine wirklich optimale Lösung gefunden.
Der echte Mehrwert von WKS liegt ja darin das man unstrukturierten Text analysieren kann, aber nicht nur über Wörterbücher und Regeln sondern eben über erlernte semantische Zusammenhänge.
Dazu brauche ich natürlich die entsprechenden Texte welche
- unstrukturierte Informationen enthalten die es zu extrahieren gilt,
- viele Variationen enthalten so das ich mit traditionellen Textanalysemethoden an meine Grenzen komme,
- idealerweise eine halbwegs normale Satzstruktur aufweisen,
- für die Nutzung in meinem Blog frei verfügbar sind.
Nach langem Überlegen hab ich mich dazu entschieden als Beispiel Tweets auf Twitter zu analysieren die sich mit der aktuellen Kursentwicklung im DAX befassen.
Auch wenn Twitter sicher nicht optimal ist bezüglich der Satzstruktur und der enthaltenen Variationen glaube ich trotzdem das es eine sinnvolle Option ist. Frei verfügbare Texte mit echtem Informationsgehalt in größeren Mengen zu bekommen ist jedenfalls nicht so einfach.
Verstehen der fachlichen Anforderungen
Verproben wir mal die oben genannten Fragen gegen unsere Tweets. Als Beispiel würde ich Tweets wie diese hier nehmen:
#DAX weiter auf dem Weg nach oben. Aktuell gibt es auch keine übergeordneten Warnhinweise!- Unser
#DAX Handelssystem ist heute wieder Short zu 11.300, Stop Loss 11.324, Take Profit 11.288 - Zweiter Versuch für einen LONG Trade im
#DAX bei 11123 SL 11099 TP 11189 #DAX hat die wochenlange Seitwärtsrange nach unten verlassen#DAX erholt sich vom schwachen Wochenstart- …
Frage: Welche Informationen sollen aus den Texten extrahiert werden?
Antwort: Aktuelle Einschätzungen / Sentiment der Twitter Nutzer zum DAX Trend; Warnsignale um aktuellen Investments abzusichern; konkrete Handelsempfehlungen um diese im Nachhinein zu validieren und damit Nutzer mit hoher Trefferchance bei Tradingempfehlungen zu finden.
Fazit: Diese Informationen können wir über WKS Entitäten und Relationen aus den Texten extrahieren.
Frage: Können diese Informationen dazu beitragen das Geschäftsproblem des Kunden zu lösen?
Antwort: Unser „Geschäftsproblem“ hier ist es in einer Artikelserie die praktische Anwendung von WKS zu demonstrieren.
Fazit: Dafür sind die Tweets wohl ausreichend.
Frage: Sind diese Informationen überhaupt in den zu analysierenden Texten enthalten?
Antwort: Ja, sind enthalten aber in sehr unterschiedlicher Formulierung und unter relativ vielen irrelevanten Tweets zum Hashtag DAX verborgen.
Fazit: Sollte funktionieren, es wird aber eine größere Menge an Trainingsdaten erforderlich sein, sowohl positive als auch negative Beispiele (also Tweets mit und ohne relevanten Inhalt).
Frage: Kann eine ausreichende Anzahl von relevanten Beispieltexten für das Training bereitgestellt werden?
Antwort: Es werden täglich mehrere hundert Tweets erstellt mit dem Hashtag DAX, von daher können wir davon ausgehen das wir genügend Trainingsdaten zur Verfügung haben werden. Twitter bietet eine API für die Suche nach Tweets, daher können wir auch leicht automatisiert passende Trainingsdaten erhalten.
Fazit: Die Verfügbarkeit von Beispieltexten ist nahezu ideal.
Grundlagen des Typsystems
Das Typsystem in WKS besteht aus verschiedenen Elementen. Mentions (Erwähnungen), deren Entitätstypen sowie die Beziehungen von Erwähnungen zueinander.
Mention / Erwähnung
Eine Erwähnung (Mention) ist erst mal nur eine Textbereich der eine fachlich relevante Information benennt. In unserem Beispiel wären das unter anderem „DAX“, „Seitwärtsrange“, „Short“, „nach oben“, usw.
Fertig annotierte Mentions sehen in der Anwendung dann so aus:

Entity types / Entitätstypen
Die gefundenen Erwähnungen werden in Entitätstypen (Entity Types) eingeteilt. Diese Einteilung ist erst mal beliebig, sie sollte aber natürlich sinnvoll sein hinsichtlich den fachlichen Anforderungen.
Ziel ist es alle gefundenen fachlich relevanten Erwähnungen einem Entitätstyp zuzuordnen.
Um bei unseren Beispielen zu bleiben würden wir für die Erwähnung „DAX“ als Entitätstyp „WERTPAPIER“ vergeben.
Entitätstypen können mittels Untertypen (Subtypes) unterteilt werden um ihre Art näher zu bestimmen.
Die Begriffe „Seitwärtsrange“, „Short“, „nach oben“ würde ich zum Beispiel alle einem Entitätstyp „TREND“ zuordnen und dann Untertypen vergeben für „POSITIV“, „NEUTRAL“ und „NEGATIV“.
Man muss nicht zwingend mit Untertypen arbeiten, es kann aber sinnvoll sein um das Typsystem übersichtlicher zu halten. Im Beispiel oben könnten wir auch direkt mit den drei Entitätstypen „TREND_POSITIV“, „TREND_NEUTRAL“, „TREND_NEGATIV“ arbeiten. Bei vielen Entitätstypen besteht hier aber die Gefahr das wir das Typsystem künstlich aufblähen.
Entitätstypen können noch weitere Attribute haben auf die ich hier der Einfachheit halber nicht weiter eingehen möchte. Eventuell schreibe ich dazu später noch mal einen weiteren Artikel mit mehr Details. Diese weiteren Attribute sind Rollen (Roles), Erwähnungstypen (Mention Type) und Erwähnungsklassen (Mention Class).
Für unser Beispiel verwenden wir davon lediglich die Erwähnungsklasse um damit Negationen zu markieren (wie in „keine übergeordneten Warnhinweise“).
Relation types / Beziehungstypen
Beziehungen oder Zusammenhänge zwischen Entitäten werden in Beziehungstypen (Relation Types) eingeteilt.
Fertig annotierte Beziehungen sehen in der Anwendung so aus:
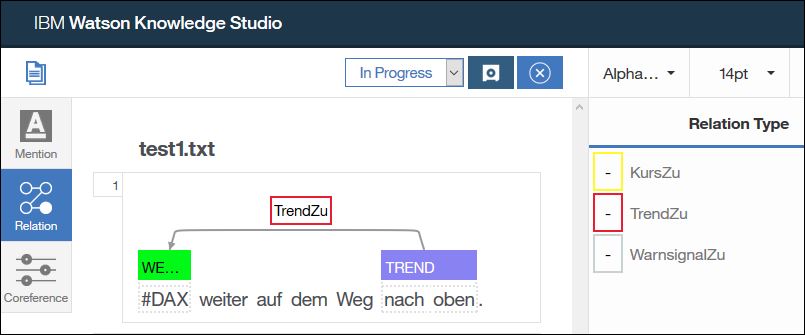
Im Satz „DAX weiter auf dem Weg nach oben“ können wir zwischen den Entitäten „nach oben“ (TREND) und „DAX“ (WERTPAPIER) eine Beziehung vom Typ „TrendZu“ markieren.
Die Richtung einer Beziehung vom Typ „TrendZu“ ist dabei immer klar, sie geht von Trend zum Wertpapier. Es gibt andere Beziehungen bei denen die Richtung nicht so klar oder nicht so wichtig ist, wie zum Beispiel wenn man eine Verwandtschaft zwischen zwei Personen markieren möchte. In diesem Fall wird meist die Erwähnung welche als erste im Text vorkommt auch als Ausgangspunkt der Beziehung verwendet.
Koreferenzen
Um eine Beziehung definieren zu können müssen die jeweiligen Entitäten im Text innerhalb des gleichen Satzes genannt sein, entweder direkt oder über eine Koreferenz (Coreference). Eine Koreferenz ist in der Regel ein Pronomen wie der/die/das oder er/sie/es usw.
Koreferenzen müssen nicht eigens eingerichtet werden, sie sind bereits standardmäßig in jedem Typsystem vorhanden.
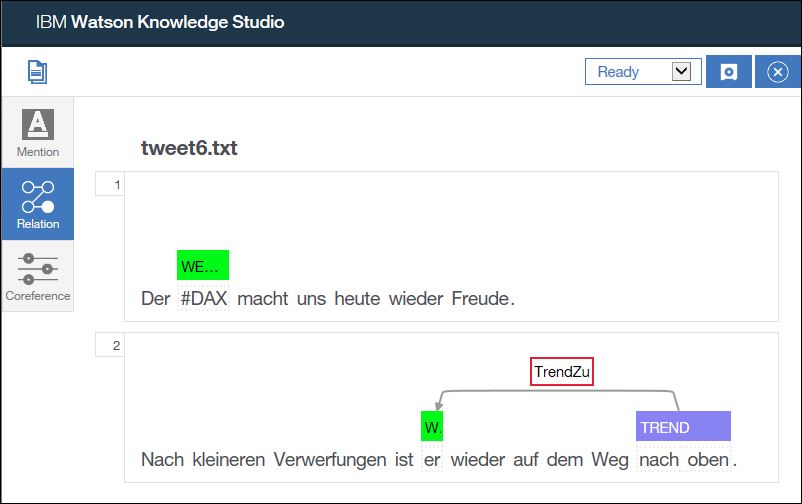
In diesem Beispiel ist das Pronomen „er“ eine Koreferenz für „DAX“, beide werden als WERTPAPIER Entität in der Farbe grün markiert. Nach dem ich „er“ dann als Koreferenz von DAX markiert habe kann die Beziehung „TrendZu“ zwischen den beiden Entitäten ziehen.
Das System lernt dadurch das sich in diesem Zusammenhang „er“ auf „DAX“ bezieht und kann das dann in seine Wissensbasis mit aufnehmen.
Entwurf des Typsystems
So lieber Leser, erst einmal meinen Glückwunsch das du bis hier her durchgehalten hast. Die Details zum WKS Typsystem sind manchmal eine etwas trockene Materie, aber als Grundlage unverzichtbar.
Der wichtigeste Satz beim Entwurf eines Typsystem ist:
Ein Typsystem ist keine Ontologie!
Man sollte also nicht den Fehler machen mit dem Typsystem die komplette Domäne des Kunden modellieren zu wollen. Konkret sind es folgende drei Fragen die jede Entität und Relation im Typsystem erfüllen muss:
- Ist die Information relevant um das konkrete Geschäftsproblem zu lösen?
- Ist die Information ausreichend oft in den Trainingsdokumenten vorhanden?
- Ist die Information hinreichend gut von den anderen Informationen abgrenzbar (z.B. nicht überlappend mit anderen Erwähnungen)?
Wenn eine dieser Fragen nicht bedingungslos mit „Ja“ beantwortet werden kann, dann sollte man den Typ erst mal weglassen.
Grundsätzlich ist es besser mit einem einfachen Typsystem zu starten und danach gezielt die Komplexität zu erhöhen. Das macht auch das Annotieren der Dokumente für den Fachbereich einfacher und schneller.
So würde ich nun also das konkrete Typsystem für unser Beispiel entwerfen:
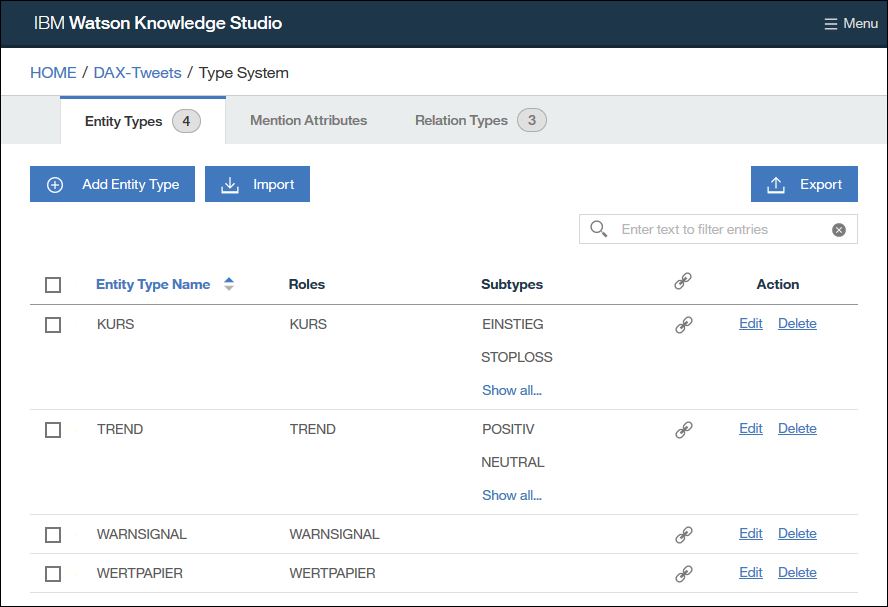
Entity Types / Entitätstypen
| Entitätstyp | Untertyp | Beispiele |
| WERTPAPIER | NONE | DAX, Index, Aktie, ABC AG, … |
| TREND | POSITIV | Aufwärtstrend, nach oben, long |
| NEUTRAL | Seitwärtsrange, neutral | |
| NEGATIV | Abwärtstrend, nach unten, short | |
| KURS | NONE | 11.345, 35,23 |
| EINSTIEG | 11123 | |
| STOPLOSS | 11099 | |
| ZIEL | 11189 | |
| WARNSIGNAL | NONE | Warnhinweise (Negationen „keine Warnhinweise“ werden markiert mit Klasse NEG) |
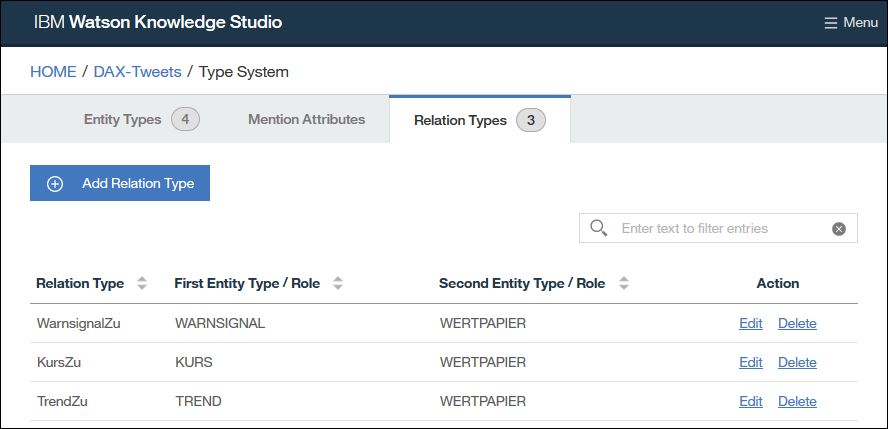
Relation Types / Beziehungstypen
| Relationstyp | Quellentität (von) | Zielentität (zu) | Beispiele |
| TrendZuWertpapier | TREND | WERTPAPIER | DAX … short |
| KursZuWertpapier | KURS | WERTPAPIER | DAX … 11123 |
| WarnsignalZuWertpapier | WARNUNG | WERTPAPIER | DAX … Warnhinweise |
In welche „Richtung“ so eine Relation zeigt ist erst mal egal. Wir könnten hier durchaus die Relationen auch anders herum modellieren, z.B. „WertpapiertHatTrend“.
Wichtig ist nur das die Richtung konsistent ist. Für den Algorithmus den wir später trainieren wollen ist die Richtung egal, aber die Benutzer haben es bei der Annotation der Trainigsdokumente wesentlich leichter wenn z.B. alle Relationen zu WERTPAPIER hin zeigen oder von WERTPAPIER ausgehen.
Das Anlegen dieses Typsystems im WKS ist dann recht einfach. In der Anwendung sieht das dann folgendermaßen aus:
Mehr Informationen zum Typsystem gibt es in Englisch unter den folgenden Links:
- Establishing a type system
- Video: Watson Knowledge Studio Deep Dive – Domain Adaptation
- Video: Watson Knowledge Studio Deep Dive – Type System
Im nächsten Artikel dieser Serie „Wissenstransfer vom Mensch zur Maschine mit IBM Watson Knowledge Studio“ beschreibe ich wie wir anhand des Typsystems Beispieldokumente annotieren um damit das Grundwissen für das maschinelle Lernen des Systems zu erstellen.