Maschinelles Lernen bezeichnet die automatische Generierung von Wissen auf Basis von vorgegebenen Lerndaten. Es wird genutzt um ein künstliches neuronales Netz zu trainieren.
Normalerweise wird das neuronale Netz dabei mit bestehenden Daten trainiert. Das nennt sich dann „Überwachtes Lernen“. D.h. ich gebe der KI vor für welche Eingabewerte ich welches Ergebnis erwarte. Das sind die Lerndaten.
Typische Anwendungsfälle für maschinelles Lernen sind Bilderkennung, Spracherkennung, Klassifizierung, Vorhersagemodelle und das Finden von Entitäten in Texten. Für jede dieser Anwendungsfälle benötigt man jeweils unterschiedliche Lerndaten.
Die Lerndaten, das „Grundwissen“, wird im Englischen als „Ground Truth“ bezeichnet und besteht meistens aus mehreren hundert bis tausenden Datensätzen.
Die Qualität der Lerndaten ist dabei entscheidend für den Erfolg des maschinellen Lernens. Bei einem Machine Learning Projekt wird daher auch die meiste Zeit für die Erstellung dieser Lerndaten verwendet.
Während der Lernphase versucht das System nun aus diesen Lerndaten Muster und Gesetzmäßigkeiten abzuleiten. Im Idealfall lernt das System also nicht die richtigen Ergebnisse für die entsprechenden Eingabedaten auswendig sondern erzeugt intern einen Lösungsweg wie es von den Eingabewerten auf das passende Ergebnis kommt.
Wie macht die KI das nun?
Die eigentliche Lernphase ist mit sehr viel Mathematik verbunden, mehr als ich hier darstellen möchte. Aber im Prinzip geht es darum die Gewichtungen der Verbindungen der künstlichen Neuronen so lange zu verändern bis ein lokales Minimum bezüglich der Fehlerrate erreicht ist.
…
OK, vielleicht noch mal in einfach und mit Beispiel:
Ein künstliches neuronales Netz besteht aus künstlichen Neuronen. Diese sind im mehrere Schichten aufgeteilt. Ein Neuron (hier B) in einer bestimmten Schicht (hier N) ist mit allen Neuronen in der vorherigen Schicht (hier A1 und A2 in Schicht N-1) verbunden.
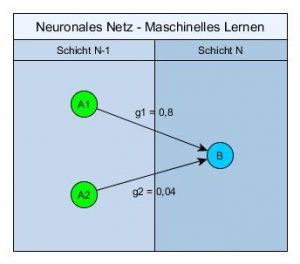
Jede dieser Verbindung hat ein bestimmtes Gewicht (hier g1 und g2).
Das heisst für unser betrachtetes Neuron (B) gibt es in der vorherigen Schicht wichtigere Neuronen (A1) und unwichtigere Neuronen (A2).
Wenn jetzt von den wichtigen Neuronen in der vorherigen Schicht genügend aktiv werden dann wird auch unser betrachtetes Neuron auslösen.
Während der Lernphase werden nun genau diese Gewichtungen permanent verändert bis die Fehlerrate am geringsten ist. Um genau zu sein werden die Gewichtungen verändert wenn in der letzten Schicht, der Ausgabeschicht, ein falsches Ergebnis herauskommt. Dieses Verfahren nennt sich dann „Backpropagation of Error“.
Man kann also sagen das ein neuronales Netz aus seinen Fehlern lernt.
Nach Abschluß der Lernphase sollte man die gelernten Regeln überprüfen. Dazu hält man normalerweise von den Lerndaten einen bestimmten Anteil, z.B. 20% zurück und überprüft das System nach dem Lernen mit diesen weiteren Daten. Wenn auch für diese Daten überwiegend die erwarteten Ergebnisse herauskommen dann hat man ein sehr gut trainiertes System.
Falls nicht dann kann es sein das das System nur die Lerndaten „auswendig“ gelernt hat. Das nennt sich dann „Overfitting“ oder auf Deutsch „Überanpassung“.
Es gibt unterschiedliche Methoden so eine Überanpassung zu vermeiden. Zum Beispiel durch die Nutzung von Drop-Out-Schichten. Dabei werden aus dem ganzen neuronalen Netz nach der Lernphase eine komplette Schicht Neuronen entfernt. Scheint ganz gut zu funktionieren in der Realität, auch wenn es sich im ersten Moment etwas komisch anhört.
Deep Learning
Zum Schluß noch ein paar Worte zum Thema „Deep Learning“.
Moderne künstliche neuronale Netze werden auch als „Deep Neural Networks“, also „Tiefe neuronale Netze“ bezeichnet. Das „tief“ bezieht ich dabei lediglich auf die Anzahl der versteckten Schichten, jedes Netz mit mehr als einer versteckten Schicht darf sich dabei schon „tief“ nennen, der Begriff ist nirgends wirklich definiert.
Und „Deep Learning“ bedeuted eben solch ein tiefes neuronales Netz entprechend zu trainieren. Die dazu notwendige Rechenpower steht erst seit wenigen Jahren flächendeckend zur Verfügung, auch bei den Trainingsalgorithmen für Deep Learning hat sich erst in den letzten Jahren sehr viel getan.
Das sind auch die Gründe dafür warum das Thema „Künstliche Intelligenz“ aktuell wieder so gehypt wird, nach dem es ja Ende des letzten Jahrhunderts schon mal total out war.
Und sonst?
In meiner Artikelserie „Maschinelles Lernen in der Praxis: IBM Watson Knowledge Studio“ habe ich ein Beispiel beschrieben wie man maschinelles Lernen praktisch anwenden kann.